

Datastrukturer
Inom programmering är en ‘datastruktur’ en struktur för att organisera data. Valet av datastruktur är viktigt då de har olika betydelse för prestanda och presterar olika beroende på vilka algoritmer som har planerats att användas. En datastruktur är en abstrakt beskrivning till skillnad från ‘datatyper’. En datatyp kan vara exempelvis Integer, String eller boolean. Det har en fast betydelse medan en datastruktur beskriver något odefinierbart, till exempel en lista eller array.
Det finns många olika datastrukturer i olika kategorier. Vi har “Linjära datastrukturer” (Lista, Stack, Kö, etc.). En annan struktur-kategori som har en stor plats inom programmering är “Träd”. De är lite mer komplexa än till exempel en Stack.
Många datastrukturer finns redan inbyggda i programmeringsspråken (tex lista i Python) och det finns färdiga moduler och bibliotek som har strukturen implementerad och klar. Det är dock viktigt att ha en insikt i hur de fungerar “på insidan”.
I artikeln kommer det tas upp tre olika datastrukturer.
* Stack (Linjär datastruktur)
* Kö (Linjär datastruktur)
* Länkad lista (Linjär datastruktur)
#Förutsättning
Du kan grunderna i Python och objektorientering. Du har jobbat igenom övningen exceptions.
#Stack

En Stack är en linjär datastruktur som påminner om, precis som det låter, en trave eller stapel. Tänk dig en stapel med tallrikar där en tallrik representerar ett objekt, variabel eller vad det nu är man lagrar. För att hantera “insättning och uttag” arbetar man från toppen. Arbetssättet kallas “LIFO” (Last In First Out). En Stack innehåller samma datatyp.
Man använder sig oftast av en särskild uppsättning metoder:
1. .push() (Lägger till)
2. .pop() (Tar bort)
3. .peek() (Visar vad som ligger överst utan att ändra i stacken)
4. .is_empty() (Returnerar True/False beroende på om stacken är tom)
5. .size() (Returnerar antal element i stacken)

En Stack med specifierat antal platser.
En implementation av en Stack kan se ut som följer:
class Stack:
def __init__(self):
self._items = []
def is_empty(self):
return self._items == []
def push(self, item):
self._items.append(item)
def pop(self):
try:
return self._items.pop()
except IndexError:
return "Empty list."
def peek(self):
return self._items[len(self._items)-1]
def size(self):
return len(self._items)
Att arbeta med stacken kan gå till så här:
>>> from stack import Stack
>>> myList = Stack()
>>> myList.push(3)
>>> myList.push(19)
>>> myList.push(5)
>>> myList.peek()
5
>>> myList.pop()
5
>>> myList.peek()
19
>>> myList.size()
2
>>> myList.is_empty()
False
>>> myList.pop()
19
>>> myList.pop()
3
>>> myList.pop()
'Empty list.'
>>> myList.size()
0
#Queue

En Queue (kö) är en linjär datastruktur som påminner om en Stack. Skillnaden är att en Kö är öppen i båda ändar. Den ena änden används för att lägga till element och den andra för att ta bort element. Arbetssättet kallas “FIFO” (First In First Out).
Metoderna som används är vanligtvis:
1. .enqueue() (Lägger till)
2. .dequeue() (Tar bort)
3. .peek() (Visar vad som ligger överst utan att ändra i kön)
4. .is_empty() (Returnerar True/False beroende på om kön är tom)
5. .size() (Returnerar antalet element i kön)
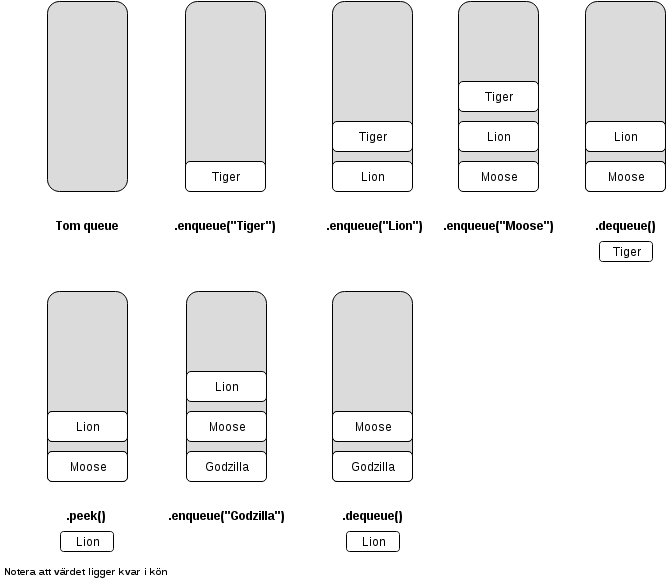
En kö utan specifierat antal platser.
En implementation av en Queue kan se ut som följer:
class Queue:
def __init__(self):
self._items = []
def is_empty(self):
return self._items == []
def enqueue(self, item):
self._items.append(item)
def dequeue(self):
try:
return self._items.pop(0)
except IndexError:
return "Empty list."
def peek(self):
return self._items[0]
def size(self):
return len(self._items)
Att arbeta med en Queue:
>>> from queue import Queue
>>> myList = Queue()
>>> myList.is_empty()
True
>>> myList.enqueue("Tiger")
>>> myList.enqueue("Lion")
>>> myList.enqueue("Moose")
>>> myList.is_empty()
False
>>> myList.dequeue()
'Tiger'
>>> myList.peek()
'Lion'
>>> myList.enqueue("Godzilla")
>>> myList.dequeue()
'Lion'
#Länkad lista
För både Queue och Stack har vi använt oss av Pythons inbyggda List:a för att lagra värden, så än så länge har vi bara gjort en specialversion av Pythons List. Tanken är att vi inte ska behöva List utan att vi ska bygga hela datastrukturen själva. För att lyckas med det ska vi använda oss av noder och kommer bygga en egen länkad lista. Queue och Stack är även bara en specialversion av Länkad lista.
Vi kan tänka oss en vanlig List/Array som bilden nedan. Arrayen ligger sparad i minnet som en bit och i den biten ligger värdena ordnade efter varandra. Då behöver vi inte ha koll på var varje värde ligger utan bara arrayen.
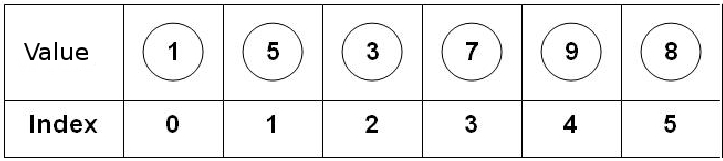
Array i minnet
För en länkad lista med noder kan vi inte göra antagandet att värdena ligger intill varandra utan de allokeras till olika platser i minnet. Därför måste varje värde i den Länkade listan vara länkad till nästa värde. Det använder vi en Node klass för.
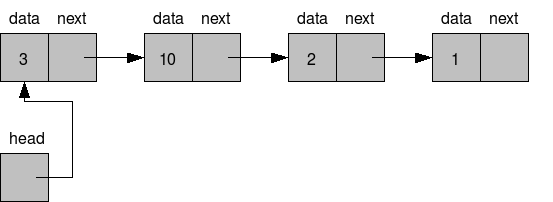
Länkad lista med noder
Den enklaste versionen av en Node klass innehåller bara två attribut, ett för att hålla data och ett för att hålla koll på nästa nod. Den första noden i en icke-tom lista kallar vi för head, huvudet av listan. För att komma åt noderna i en länkad lista måste det finnas en referens till huvudet. Från huvudet kan vi komma åt resterande noder genom att följa pekarna i noderna. Den sista nodens next attribut innehåller None för att visa att det är sista noden.
Listan på bilden kallas enkellänkad lista. Det finns även dubbellänkade listor, då är varje nod kopplad till noden före och efter.

Enkel- och dubbellänkade noder
En annan vanlig typ är Cirkulär länkad lista. I en Cirkulär länkad lista är sista noden länkad till den första.

Cirkulär Enkellänkad lista
Sen finns det så klart också Cirkulär dubbellänkad lista och de kan vara sorted eller unsorted. En sorted lista sorterar automatiskt lista. När man lägger in ny data i listan letas hela listan igenom för att hitta rätt plats i ordningen. En unsorted lista lägger enbart till värdet, oftast sist i listan.
#Nod klassen
Då ska vi titta på hur koden kan se ut för nod klassen. Det behövs väldigt lite kod då vi enbart behöver ett attribut för data och ett för nästa nod.
class Node():
"""
Node class
"""
def __init__(self, data, next_=None):
"""
Initialize object with the data and set next to None.
next will be assigned later when new data needs to be added.
"""
self.data = data
self.next = next_
Vi testar använda den i python3 interpretatorn.
>>>head = Node(1)
>>>head
<__main__.Node object at 0x743545132>
>>>head.data
1
Vi har skapat ett Node objekt och testat skriva ut det och dess data.
Nu ska vi skapa ett till objekt och koppla ihop vår head med det nya.
>>>n2 = Node(32)
>>>n2.data
32
>>>head.next
>>>head.next = n2
>>>head.next
<__main__.Node object at 0x7453468745>
# Första nodens värde
>>>head.data
1
# Andra nodens värde
>>>head.next.data
32
När vi printar head.next första gången får vi ingen output för värdet är None. Efter vi tilldelat “head.next” till n2 innehåller “head.next” vårt “n2” objekt. Då kan vi skriva head.next.data för att komma åt datan, 32 i “n2” objektet.
Testa själva att skapa en till nod, n3, och tilldela till n2.next. Skriv ut “n3’s” värde via head.next.next.data och n2.next.data. På detta sättet kan vi bygga upp en länkad lista.
#Traversera noder
Att börjar vid en listas huvud och gå igenom alla noder och göra något med dem kallas att traversera en lista. T.ex. behöver vi traversera en lista om vi vill skriva ut alla noders värden. Det gör vi lättast genom att skapa en ny variabel som används för att peka på listans huvud och använda den för att traversera listan.
number_list = Node(3) # Create first node, head
temp = Node(2) # Create Node and assign to temp variable
temp.next = Node(4) # Create Node and assign to temp.next
number_list.next = temp # Assign temp to number_list.next
Ovanför skapar vi en enkel lista, number_list som innehåller [3, 2, 4]. För att skriva ut alla värden använder vi en while-loop.
current_node = number_list
while current_node != None:
print(current_node.data) # Print nodes value
current_node = current_node.next # Move to next node
I loopen ersätter vi pekaren, current_node, med nästa nod och på så sätt traverserar vi listan utan att förändra den. number_list innehåller fortfarande samma struktur.
#Hämta värde med index
Nu ska vi hämta ut ett värdet vid med ett index.
def get(index, head):
# Get value by index
if head is not None:
current_node = head
counter = 0
pass
else:
pass
# Raise exception for index out of bound
Vi börjar med att kolla att den första noden inte är None, alltså att listan är tom. Sen skapa vi variabeln current_node som vi kommer använda när vi traversera för att hålla noden vi är på. counter används för räkna vilket index vi är på. Om listan då är tom, head == None, vet vi att vad än index är så kommer det vara out-of-bound och ska då lyfta ett exception.
Nu lägger vi till loop:en som går igenom listan.
def get(index, head):
# Get value by index
if head is not None:
current_node = head
counter = 0
while current_node.next is not None and counter < index:
current_node = current_node.next
counter += 1
else:
pass
# Raise exception for index out of bound
Vi har en “while” loop som kör så länge det finns en nästa nod, alltså head.next inte är None, och vår räknare är under index. index ska innehålla vilket index vi vill hämta värdet från. Om “next” inte är “None” ändrar vi current_node till nästa nod och ökar räknaren med ett. Med andra ord fortsätter loopen antingen tills listan är slut eller counter == index.
def get(index, head):
# Get value by index
if head is not None:
current_node = head
counter = 0
while current_node.next is not None and counter < index:
current_node = current_node.next
counter += 1
if counter == index:
return current_node.data
else:
# Raise exception for index out of bound
raise IndexError()
else:
# Raise exception for index out of bound
raise IndexError()
Efter vår while loop behöver vi kolla om den tog slut för att index är för högt eller om vi har hittat index. Om vi är på index printar vi värdet annars lyfter vi ett index-out-of-bounds error.
Detta är ett sätt att skriva koden för att leta igenom en lista för ett index, det finns minst 20 andra sätt att skriva den på. Försök gärna komma på andra sätt att skriva den.
Vi testar använda funktionen också.
number_list = Node(1)
number_list.next = Node(2, Node(3, Node(4)))
print(get(0, number_list))
# 1
print(get(3, number_list))
# 4
print(get(5 , number_list))
# IndexError
Nu har vi kod för att hämta från en länkad lista och även sett hur vi kan koppla ihop flera noder. Hur gör vi för att ta bort en nod från listan?
#Ta bort nod
För att ta bort en nod behöver vi använda oss av två variabler när vi traveserar oss igenom listan. Vi behöver current_node och previous, används current_node för att travesera fram till noden som ska raderas. previous ska alltid peka på föregående nod, noden före current_node. När vi har hittat rätt nod kopplar vi om noden i previous så den pekar på noden efter current_node. Sist radera vi noden vi vill ta bort, del temp.
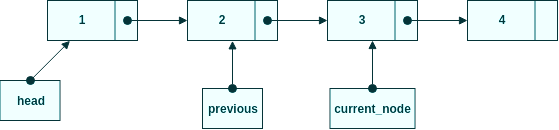
Hitta rätt noder
Steg 1, travesera igenom noderna så current_node pekar på den som ska raderas och previous pekar på föregående nod.
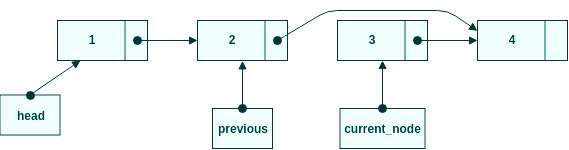
Länka om previous.next till current_node.next
Steg 2, tilldela current_node.next till previous.next.
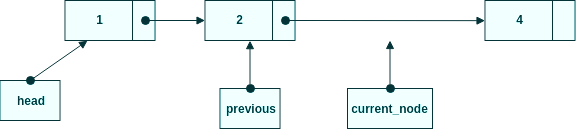
Radera current_node
Steg 3, radera current_node.
#Lägg till nod
När vi ska lägga till en nod är det viktigt med vilken ordning vi gör saker annars kan vi tappa alla noder som ska vara efter den nya vi lägger till. I bilden nedan utgår vi från listan [1, 2, 4] och vi vill stoppa in en ny nod, med siffran 5 som värde, mellan 2 och 4. Listan ska se ut [1, 2, 5, 4] när den är klar.
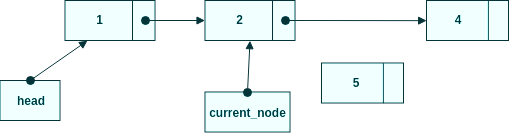
Hitta rätt nod och skapa ny
Steg 1, travesera igenom noderna så current_node pekar på den nod som ska ligga före den nya.
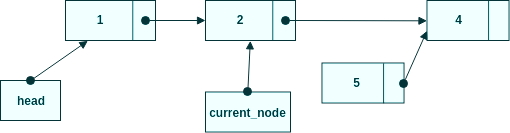
Sätt new_node.next till current_node.next
Steg 2, tilldela current_node.next till new_node.next. Så båda pekar på samma nod.
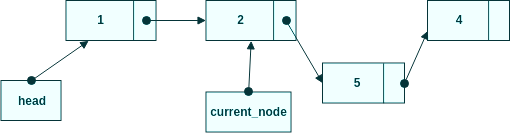
Sätt current_node.next till new_node.
Tilldela new_node till current_node.next så vi har en komplett lista igen. Om vi gör det i den här ordningen behöver vi inte vara oroliga för att tappa några noder. Fundera på vad som hade hänt om vi hade skippat steg 2 och istället direkt tilldelade den nya noden till current_node.next.
#Avslutningsvis
Nu har ni lärt er några olika datastrukturer, de har olika för och nackdelar som spelar roll när man ska välja en. Kolla igenom Choosing the Right Data Structure to solve problems för att se vilka olika för- och nackdelar datastrukturerna som ni läst om har.
Det finns som sagt många sorters datastrukturer. För en lista kan du kika på: List of datastructures. Här har vi tagit upp tre utav de vanligaste. Hoppas du har fått en liten insikt i hur de fungerar.
#Revision history
- 2024-01-26: (D, aar) Uppdatera så attribut är privata.
- 2019-01-31: (C, aar) Tog bort sektionen om Heap.
- 2019-01-25: (B, aar) Bytte ut bilder och lite text.
- 2017-02-08: (A, lew) First version.

