

Vad är Regex?
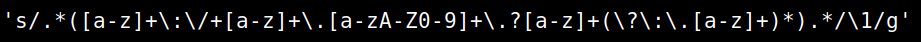
Regex är en förkortning av Regular Expression (reguljära uttryck) som är ett välkänt verktyg för att matcha textmönster. Det används oftast till att extrahera information från kod, loggfiler och andra texter.
I regex definieras ett mönster av karaktärer som regex sedan försöker hitta/matcha i en sträng eller text.
Om ni har svårt att förstå ett regex mönster eller ni vill testa mönstret på en text, snabbt och lätt, rekommenderar jag sidan https://regex101.com/. Du skriver in ett mönster och en text där förklarar de olika delarna i mönstret och visar på ett bra sätt vad som matchas.
Notera dock att den sidan använder andra flavours (PCRE, PHP, ES, Python, Golang etc).
Ett annat bra verktyg online är https://regexone.com/.
#Special Characters
I regex har vissa karaktärer en speciell betydelse, det är detta som gör att vi kan matcha mönster dynamiskt och inte enbart fasta strängar. Man kan inte ta för givet att alla speciella karaktärer fungerar i alla dialekter av regex, men det ger en fingervisning på vad som oftast finns tillgängligt.
#Characters
.(punkt): Matchar vilken karaktär som helst utom newline(\n). Kallas även wildcard.
^: Matchar början av en sträng.
$: Matchar slutet av en sträng.
|: Funkar som en “OR” operator.
[ ]: Matchar en av karaktärerna som har skrivits inom hakparenteserna.
[^ ]: Matchar en karaktär som inte har skrivits inom hakparenteserna.
\w (litet w): Matchar en alfanumerisk karaktär, alla bokstäver(stora och små), siffror och _(understreck). Kan även skrivas som [a-zA-z0-9_].
\W (stort W): Matchar en icke alfanumerisk karaktär, alltså en karaktär som inte matchas av \w. Kan även skrivas som [^a-zA-Z0-9_].
\d: Matchar en siffra. Kan även skrivas som [0-9].
\D: Matchar en karaktär som inte är en siffra. Kan även skrivas som [^0-9].
\s (litet s): Matchar en blank(whitespace) karaktär. Kan även skrivas som [ \t\n\r\f\v].
\S (stort S): Matchar en icke-blank(whitespace) karaktär. Kan även skrivas som [^ \t\n\r\f\v].
( ): Grupperar karaktärer i en matchad sträng. Det går att plocka ut grupper ur matchade strängar och det går även att refererar tillbaka till grupper i mönstren.
\: Används för att göra en specialkaraktär till en vanlig karaktär, t.ex. \. matchar en punkt istället för att fungera som ett wildcard, \* matchar en asterisk istället för att fungera som en repeterare och \( matchar en parentes istället för att starta en grupp.
Det används även för att referera till en grupp, \1 refererar till grupp 1 och \2 till grupp 2. Grupper börjar på 1 och uppåt.
#Quantifiers
En så kallad quantifier används för att upprepa ett mönster ett visst antal gånger. Dessa tecken brukar antingen vara lazy eller greedy. Med lazy menas att det kommer vara det minsta antalet matchningar som tas med och greedy är motsatsen, så många matchningar som möjligt tas med.
?: Matchar noll eller en gång.
+: Matchar en eller flera gånger.
*: Matchar noll eller flera gånger.
{ }: Matchar en intervall.
#Character classes
En character class definieras av hakparenteser, [...]. I dem kan vi bestämma vilka bokstäver som ska matchas.
[a-z] matchar alla små bokstäver mellan a och z.
[A-Z] matchar alla stora bokstäver mellan A och Z.
[a-zA-Z] matchar alla bokstäver, stora som små.
[a-g] matchar alla små bokstäver mellan a och g.
[0-9] matchar alla siffor mellan 0 och 9.
[3-5] matchar alla siffor mellan 3 och 5.
[exmpl] matchar någon av bokstäverna definierade.
#Avslutningsvis
Det här var lite om grunderna i regex. Kör igång och testa på sidorna:
Använd sedan artikeln att luta dig mot i uppgifterna.
#Revision history
- 2021-04-12: (A, lew) Första versionen.
