

Lagra innehåll i databas för webbsidor och bloggposter (v2)
Ibland vill vi hantera webbplatsens innehåll genom att lagra det i databasen. Denna artikel visar hur du bygger upp en tabell som lagringsstruktur för innehåll som kan användas till webbsidor och bloggposter. Via ett formulär kan du redigera sidans titel och innehåll som sparas undan i databasen. Det blir enkelt att uppdatera din webbsidas innehåll och visa upp den på valfri länk, utan att ha direkt tillgång till databasen eller webbservern. Det räcker med en webbläsare.
När du är klar har du byggt både webbsidor och en blogg från innehåll som du lagrat och redigerat i databasen.
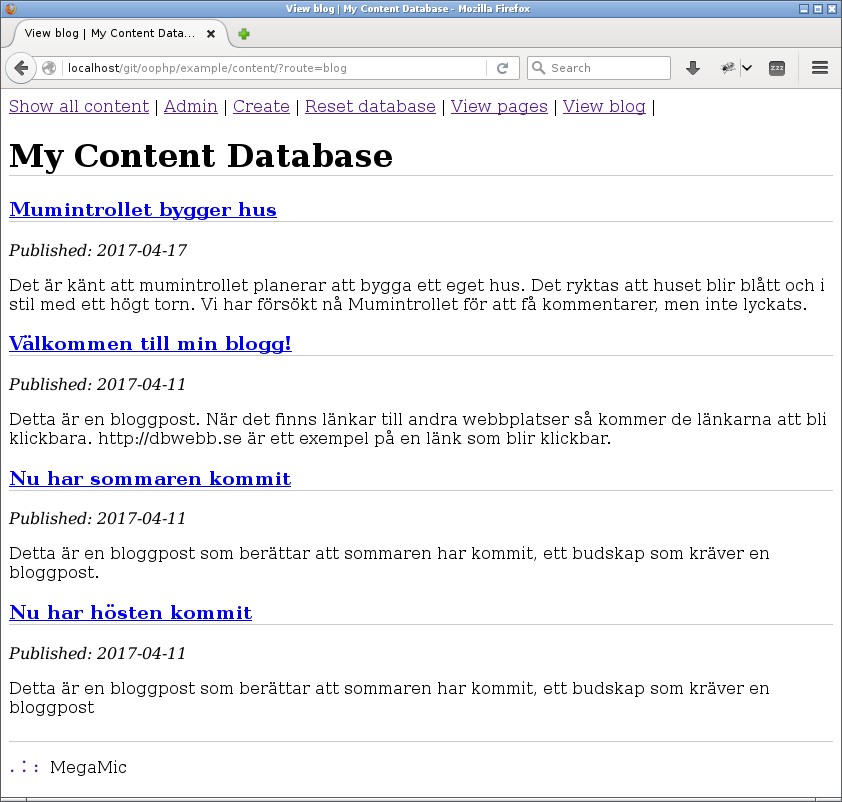
Så här kan det se ut när du jobbar i exempelprogrammet som medföljer artikeln.
Ett formulär för att jobba CRUD med innehåll i databasen.
#Förutsättningar
Du är bekant med PHP PDO och MySQL och/eller du har jobbat igenom artikeln “Kom igång med PHP PDO och MySQL (v2)”.
Exempelkoden finns i kursrepot (oophp) under example/content. Du behöver skapa databasen och tabellen innan du kan köra exempelprogrammet.
#Video intro
Det finns en videoserie “Artikel “Lagra innehåll i databas för webbsidor och bloggposter (v2)” kursen oophp” som ger en introduktion och översikt till artikeln.
#Tankar om innehåll i databasen
Låt oss fundera, varje webbsida har en <title> och bör ha en rubrik i form av en <h1>. Det skall finnas content, själva innehållet i webbsidan.
En sida kan ha en unik länk, en path till där sidan kan nås. Man skall kunna nå innehållet via en slug, en url som bygger på innehållets titel. Varianterna med path och slug är olika sätt att hitta matchande innehåll i databasen.
En sida kan ha olika status, den kan vara publicerad eller inte publicerad. Att vara inte publicerad kan innebära en arbetskopia som man inte vill visa upp förrän den är klar.
Det är bra att ha datumstämplar för när sidan skapades, uppdaterades och raderades.
En sida kan vara av en speciell typ, en typ som bestämmer hur och var sidan kan visas. Det kan vara bra att vara lite flexibel och visa sidor på olika sätt, baserade på dess typ. Till exempel så visar man innehåll av typen “post” i bloggen och innehåll av typen “page” som egna sidor.
Innehållet i sidan skulle kunna filtreras på olika sätt, vill man skriva PHP-kod i sidan, eller HTML, BBCode eller Markdown? Det kan behövas olika filter som bearbetar innehållet innan det presenteras.
Okey, det blev en del. Bäst att börja enkelt.
#En databastabell
Det första vi behöver är en lagringsstruktur för innehållet. Vi behöver fundera igenom vad vi vill och behöver lagra samt hur lagringen skall ske. Det går att justera strukturen efter hand men det är bra att tänka igenom strukturen från början. Det är främst en databastabell vi behöver, en grundstruktur för vad vi vill lagra.
Vi behöver skapa en tabell och fylla på med lite innehåll. Sedan kan vi börja jobba.
#Tabellstruktur
Jag lägger in all SQL-kod i en fil som jag sedan kan köra i Workbench eller direkt i terminalen. Det gör det enkelt att jobba och uppdatera SQL-koden efter hand.
-- Ensure UTF8 as chacrter encoding within connection.
SET NAMES utf8;
--
-- Create table for Content
--
DROP TABLE IF EXISTS `content`;
CREATE TABLE `content`
(
`id` INT AUTO_INCREMENT PRIMARY KEY NOT NULL,
`path` CHAR(120) UNIQUE,
`slug` CHAR(120) UNIQUE,
`title` VARCHAR(120),
`data` TEXT,
`type` CHAR(20),
`filter` VARCHAR(80) DEFAULT NULL,
-- MySQL version 5.6 and higher
`published` DATETIME DEFAULT CURRENT_TIMESTAMP,
`created` DATETIME DEFAULT CURRENT_TIMESTAMP,
`updated` DATETIME DEFAULT NULL ON UPDATE CURRENT_TIMESTAMP,
-- MySQL version 5.5 and lower
-- `published` DATETIME DEFAULT NULL,
-- `created` TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
-- `updated` DATETIME DEFAULT NULL, -- ON UPDATE CURRENT_TIMESTAMP,
`deleted` DATETIME DEFAULT NULL
) ENGINE INNODB CHARACTER SET utf8 COLLATE utf8_swedish_ci;
Tabellens struktur matchar de grundkrav som jag tänkt mig. Att ha både path och slug är två skilda saker, men båda skall unikt kunna peka ut ett visst innehåll.
Hur man kan jobba med tidsstämplar via DATETIME och TIMESTAMP samt ge dem default-värden och att använda konstruktionen ON UPDATE CURRENT_TIMESTAMP, har ändrats mellan versioner.
Jag använder default värden på tidsstämplarna published och created för att förenkla för mig.
Jag väljer att använda en inbyggd konstruktion för updated som heter ON UPDATE CURRENT_TIMESTAMP vilket gör att den tidsstämpeln ändras varje gång jag gör en update på tabellen. Man kan fundera på om det är bra eller ej, jag väljer här att bygga in mig i MySQL och släppa på kompabiliteten med andra databaser. Det fungerar i min domän som är detta exemplet och här tänker jag inte försöka att vara kompatibel mellan databaser.
#Tabellens innehåll
För att komma i gång så lägger jag in ett par i tabellen. Radernas innehåll visar hur jag har tänkt det skall fungera.
INSERT INTO `content` (`path`, `slug`, `type`, `title`, `data`, `filter`) VALUES
("hem", null, "page", "Hem", "Detta är min hemsida. Den är skriven i [url=http://en.wikipedia.org/wiki/BBCode]bbcode[/url] vilket innebär att man kan formattera texten till [b]bold[/b] och [i]kursiv stil[/i] samt hantera länkar.\n\nDessutom finns ett filter 'nl2br' som lägger in <br>-element istället för \\n, det är smidigt, man kan skriva texten precis som man tänker sig att den skall visas, med radbrytningar.", "bbcode,nl2br"),
("om", null, "page", "Om", "Detta är en sida om mig och min webbplats. Den är skriven i [Markdown](http://en.wikipedia.org/wiki/Markdown). Markdown innebär att du får bra kontroll över innehållet i din sida, du kan formattera och sätta rubriker, men du behöver inte bry dig om HTML.\n\nRubrik nivå 2\n-------------\n\nDu skriver enkla styrtecken för att formattera texten som **fetstil** och *kursiv*. Det finns ett speciellt sätt att länka, skapa tabeller och så vidare.\n\n###Rubrik nivå 3\n\nNär man skriver i markdown så blir det läsbart även som textfil och det är lite av tanken med markdown.", "markdown"),
("blogpost-1", "valkommen-till-min-blogg", "post", "Välkommen till min blogg!", "Detta är en bloggpost.\n\nNär det finns länkar till andra webbplatser så kommer de länkarna att bli klickbara.\n\nhttp://dbwebb.se är ett exempel på en länk som blir klickbar.", "link,nl2br"),
("blogpost-2", "nu-har-sommaren-kommit", "post", "Nu har sommaren kommit", "Detta är en bloggpost som berättar att sommaren har kommit, ett budskap som kräver en bloggpost.", "nl2br"),
("blogpost-3", "nu-har-hosten-kommit", "post", "Nu har hösten kommit", "Detta är en bloggpost som berättar att sommaren har kommit, ett budskap som kräver en bloggpost", "nl2br");
SELECT `id`, `path`, `slug`, `type`, `title`, `created` FROM `content`;
Jag lägger endast in värden i ett par av kolumnerna, det räcker som en start. Det handlar om två “page” som skall visas som egna sidor och tre “post” som blir till innehåll i min blogg.
#Läs in innehållet till databasen
Så här gör jag för att skapa tabellen och läsa in innehållet till min databas. SQL-filen ligger tillsammans med exemplet.
$ mysql -uuser -ppass oophp < sql/setup.sql
id path slug type title created
1 hem NULL page Hem 2017-04-18 09:20:28
2 om NULL page Om 2017-04-18 09:20:28
3 blogpost-1 valkommen-till-min-blogg post Välkommen till min blogg! 2017-04-18 09:20:28
4 blogpost-2 nu-har-sommaren-kommit post Nu har sommaren kommit 2017-04-18 09:20:28
5 blogpost-3 nu-har-hosten-kommit post Nu har hösten kommit 2017-04-18 09:20:28
Det fungerar lika bra att öppna och köra filen med Workbench eller någon annan klient.
#Kommentarer till lagringsstrukturen
När man skapar sina tabeller så har man också en grundtanke om hur man skall lösa sin applikation och vilka frågor man avser ställa mot databasen. Man ser till att lagra det som behövs för att applikationen skall fungera och lagra på ett sätt som gör det enkelt att ställa frågorna.
Låt oss titta på hur jag har tänkt.
#Typer page och post
Jag tänker mig två typer av innehåll, page och post.
För page tänker jag mig rena webbsidorinnehållet bygger upp en webbsida.
För post tänker jag mig en blogg med bloggposter. Det skall finnas bloggposter som visas på en sida och en översikt där alla bloggposter visas.
Två typer och två tänkta hanteringar av innehållet.
#Innehållet
Själva innehållet är kolumnerna title och data, det är det som ger sidans innehåll. Det blir bra som en <h1> följt av text. Dessutom kan kolumnen title bli en del av sidans HTMLelement <title>.
Jag tänker också använda mig av title för att skapa innehållets slug.
#Att komma åt innehållet
Det finns (minst) tre olika sätt att komma åt ett specifikt innehåll, dels via id som kan användas när användaren skall editera eller radera en sida.
Dels kan man komma åt innehållet via dess path som är en tänkt del av länken till innehållet. Det ger möjligheten att matcha en länk/route direkt till ett innehåll.
Varianten med slug är en översättning av innehållets titel som lämpar sig att använda i länkningen till sidan. En länk med en slug kan se ut så här:
https://dbwebb.se/coachen/gor-en-lasbar-url-med-slugify
Texten gor-en-lasbar-url-med-slugify är en slug till en sida som har titeln “Gör en läsbar url med slugify()”. Läs mer om en funktion som gör en slug av en sträng.
Vi har alltså tre olika sätt att peka ut det innehåll som skall hanteras. Det ger viss flexibilitet och det vill vi ha.
#Filter
Tanken är att innehållet skall processas via olika filter innan det visas upp. Detta ger möjligheten att använda olika strategier när man skriver sitt innehåll. Exempel på olika filter kan vara BBCode eller Markdown.
Här kan man till och med tillåta PHP-kod i artikeln, men det är kanske att gå till överdrift, eller iallafall en möjlighet som inte skall erbjudas var och en.
Här får man även tänka till om man skall tillåta HTML-kod i innehållet, eller om det skall filtreras bort. Att tillåta HTML-kod innebär att man även tillåter JavaScript. Vill man ge den öppningen till webbplatsens användare?
Vill du få ett smakprov på ett filter som översätter BBCode till HTML så kikar du via artikeln “Reguljära uttryck i PHP ger BBCode formattering”. Det leder till en funktion som översätter BBCode likt [b]Bold[/b] till HTML <b>Bold</b> och därigenom erbjuder vissa möjligheter för en användare att formattera sina inlägg.
#Tidsstämplar
Jag sätter fyra olika tidsstämplar. När innehållet skapas så sätts created, varje gång som innehållet uppdateras så uppdateras updated. När innehållet raderas så sätts deleted.
Tanken med deleted är att markera innehållet som raderat, utan att fysiskt ta bort det. Kanske vill man återskapa det, eller införa en hantering som liknar en papperskorg. Ett dokument som slängs i papperskorgen kan man ta upp (eller kasta bort på riktigt). En sådan hantering kan även kallas soft delete.
Den fjärde tidsstämpeln är published som sätter en tidpunkt för när innehållet är publicerat. Detta ger möjligheten att sätta ett datum i framtiden för att publicera innehållet vid en bestämd tidpunkt. Vill man inte att innehållet skall visas så kan man nollställa published till null alternativt sätta ett datum långt fram i tiden.
#Visa allt innehåll
Nu finns det en lagringsstruktur och några exempel på innehåll i tabellen. Låt oss nu att visa upp tabellens innehåll i en webbsida.
Det kan se ut så här.
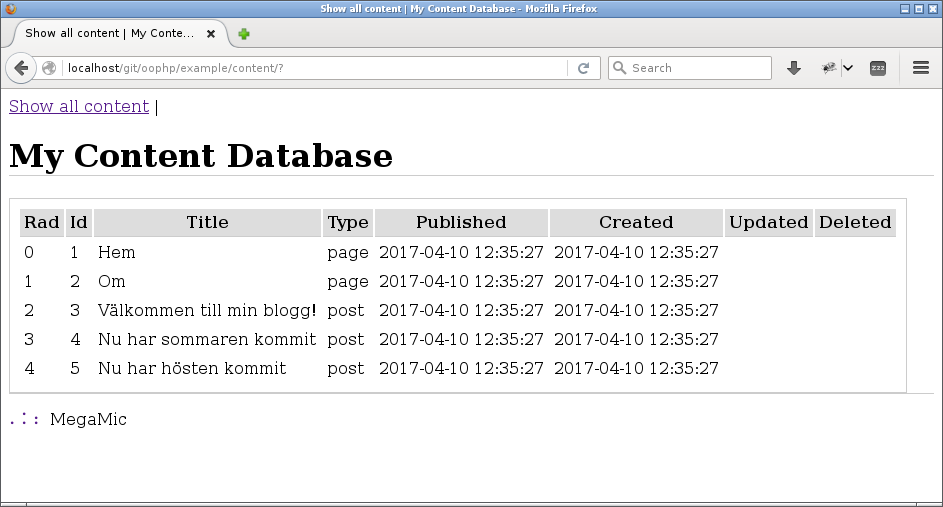
En första ansats att visa vilket innehåll som finns i databasen.
Det som behövs för att skapa ovan sida är en route motsvarande den som vi använda i film-databasen. Jag kunde nästan återanvända all min kod från det exemplet.
switch ($route) {
case "":
$title = "Show all content";
$view[] = "view/show-all.php";
$sql = "SELECT * FROM content;";
$resultset = $db->executeFetchAll($sql);
break;
Vyn innehåller koden för att översätta innehållet i $resultset till en HTML-tabell.
<?php
if (!$resultset) {
return;
}
?>
<table>
<tr class="first">
<th>Rad</th>
<th>Id</th>
<th>Title</th>
<th>Type</th>
<th>Published</th>
<th>Created</th>
<th>Updated</th>
<th>Deleted</th>
</tr>
<?php $id = -1; foreach ($resultset as $row) :
$id++;
?>
<tr>
<td><?= $id ?></td>
<td><?= $row->id ?></td>
<td><?= $row->title ?></td>
<td><?= $row->type ?></td>
<td><?= $row->published ?></td>
<td><?= $row->created ?></td>
<td><?= $row->updated ?></td>
<td><?= $row->deleted ?></td>
</tr>
<?php endforeach; ?>
</table>
Jag bygger alltså vidare på samma kodstruktur som jag använde i exemplet med film-databasen. Det känns som en enkel och ren struktur för att bygga ett exempelprogram och ändå jobbar med routes, vyer och hålla koden hyggligt separerad.
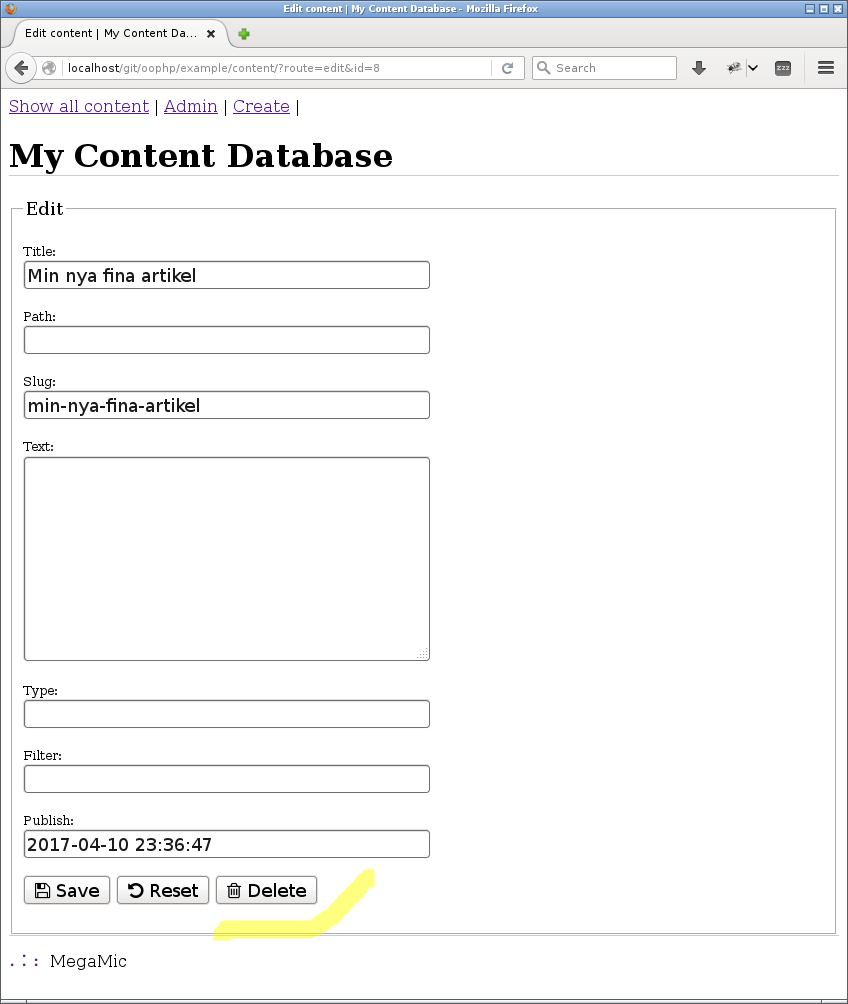
#Uppdatera innehållet
Nu behövs ett gränssnitt till användaren så innehållet kan uppdateras via webben. Det får bli CRUD-relaterade operationer på innehållet.
#Route och formulär
Jag börjar med en enklare variant av vyn show-all som visar detaljer om innehållet tillsammans med en edit-knapp från FontAwesome.
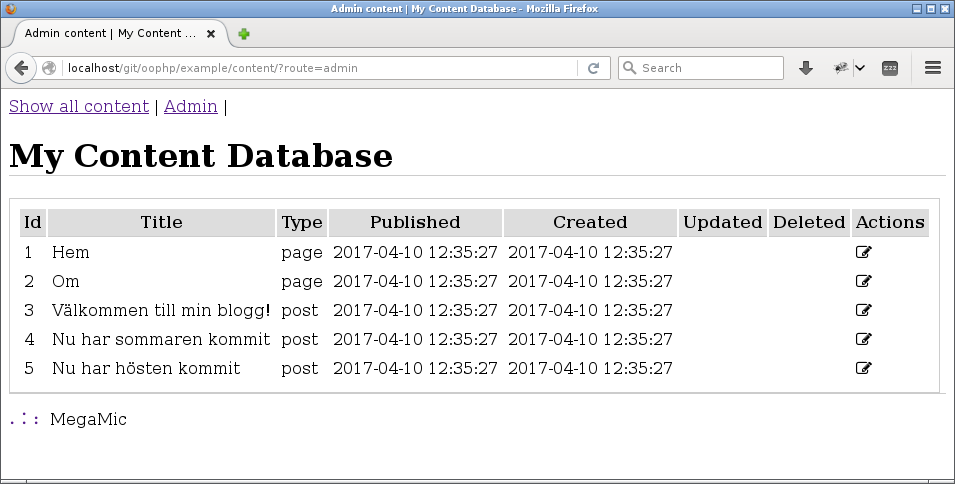
Ett admin-gränssnitt för att hantera innehållet.
Routen till edit-formuläret för översta raden blir här ?route=edit&id=1.
Nu behöver jag ett edit-formulär. Det kan se ut så här.
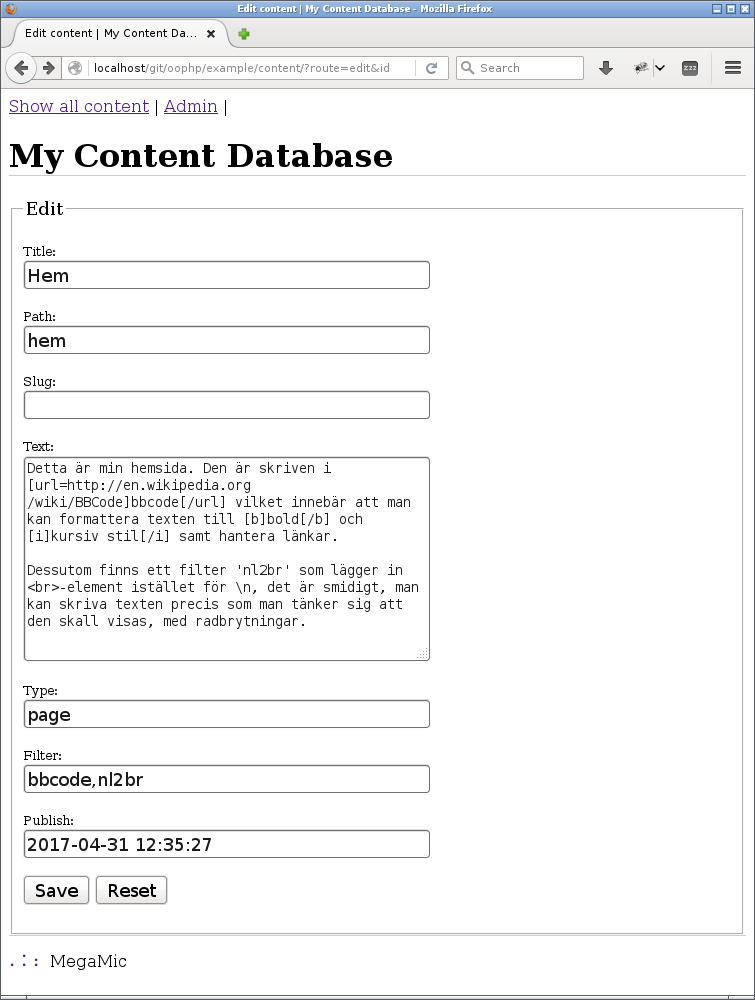
Innehållet kan nu redigeras i ett formulär.
Vi kan kika kort på routen som hanterar och förbereder för edit-formuläret.
case "edit":
$title = "Edit content";
$view[] = "view/edit.php";
$contentId = getGet("id");
$sql = "SELECT * FROM content WHERE id = ?;";
$content = $db->executeFetch($sql, [$contentId]);
break;
Vi hämtar innehållets id från querysträngen och använder det för att hämta ut rätt innehåll från databasen. Här vet vi att det bara finns en rad att hämta ut så vi använder metoden PDO::fetch() (via klassen Database) för att endast hämta första raden.
I vyn byggs formuläret upp med dess innehåll. Här är det klokt att använda htmlentities() (eller htmlspecialchars()) och jag gör det via min egna wrapper esc().
Här kan du se vissa delar av vyns källkod till formuläret.
<p>
<label>Slug:<br>
<input type="text" name="contentSlug" value="<?= esc($content->slug) ?>"/>
</p>
<p>
<label>Text:<br>
<textarea name="contentData"><?= esc($content->data) ?></textarea>
</p>
<p>
<label>Publish:<br>
<input type="datetime" name="contentPublish" value="<?= esc($content->published) ?>"/>
</p>
Det kan också var en idé att styla till sitt formulär så att det ser lite vänligare ut. Jag gör lite enklare styling.
input[type=text],
input[type=datetime],
textarea {
width: 400px;
}
textarea {
height: 200px;
}
label {
font-size: small;
}
input,
textarea,
legend {
font-size: large;
}
Då ska vi se vad som bör hända när man klickar på Spara-knappen.
#Spara uppdaterat innehåll
Jag använder mig av ett selfsubmitting formulär som postar sig till samma route som visar formuläret. Tanken är att här fånga in alla delar från formuläret och bygger upp en array med parametrar som skickas med SQL UPDATE uttrycket för att uppdatera innehållet i databasen.
Det vi vill uppnå ser ut så här.
if (hasKeyPost("doSave")) {
//$params gets all values from getPost()
$sql = "UPDATE content SET title=?, path=?, slug=?, data=?, type=?, filter=?, publish=? WHERE id = ?;";
$db->execute($sql, array_values($params));
header("Location: ?route=edit&id=$movieId");
exit;
}
Kolumnen update bör nu uppdateras automatiskt av MySQL.
Finns det ett smartare, och någorlunda kontrollerar sätt, att fylla på arrayen $params utifrån POST?
Ja, vi skulle kunna uppdatera funktionen getPost() till att stödja följande usecase och hämta många värden på en gång och returnera i en array.
//$params gets all values from getPost()
$params = getPost([
"contentTitle",
"contentPath",
"contentSlug",
"contentData",
"contentType",
"contentFilter",
"contentPublish",
"contentId"
]);
Ovan sparar vi ett antal anrop till getPost(), vi hade annars behövt ett funktionsanrop för varje värde vi vill hämta.
Vi uppdaterar funktionen så den ser skillnad på om det är en sträng eller array som kommer i första argumentet.
/**
* Get value from POST variable or return default value.
*
* @param mixed $key to look for, or value array
* @param mixed $default value to set if key does not exists
*
* @return mixed value from POST or the default value
*/
function getPost($key, $default = null)
{
if (is_array($key)) {
$key = array_flip($key);
return array_replace($key, array_intersect_key($_POST, $key));
}
return isset($_POST[$key])
? $_POST[$key]
: $default;
}
I koden ovan så bygger vi ut funktionen getPost() till att tolka inkommande argument till funktionen och utföra olika saker beroende av det är en sträng eller en array som skickas via $key.
Som du ser kan det vara bekvämt att ha koll på de inbyggda array-funktionerna i PHP. Där kan finnas viss tid och kodrader att spara. Ovan konstruktion hämtar hem värdena från POST som matcher de nycklar som angavs i $key.
Man kunde löst samma sak med en enkel loop också.
if (is_array($key)) {
// $key = array_flip($key);
// return array_replace($key, array_intersect_key($_POST, $key));
foreach ($key as $val) {
$post[$val] = getPost($val);
}
return $post;
Ibland vinner man på de inbyggda funktionerna men ibland går det likabra att lösa det själv med en enkel loop.
#Generera en slug
Nu kan vi även lösa vår slug. Den skall skapas utifrån innehållets titel och vi kan använda en funktion liknande den vi finner i “Gör en läsbar url med slugify()”.
Jag väljer att generera en slug om fältet är tomt. Då kan användaren själv skapa sin slug och i annat fall så sköts det automatiskt.
Förutsatt att funktionen slugify() finns på plats så kan jag lösa det så här.
if (!$params["contentSlug"]) {
$params["contentSlug"] = slugify($params["contentTitle"]);
}
Det blir både automatik så att slugen automatgenereras och det ger användaren möjlighet att själv sätta slugen.
Men vad händer om det blir två likadana slugs?
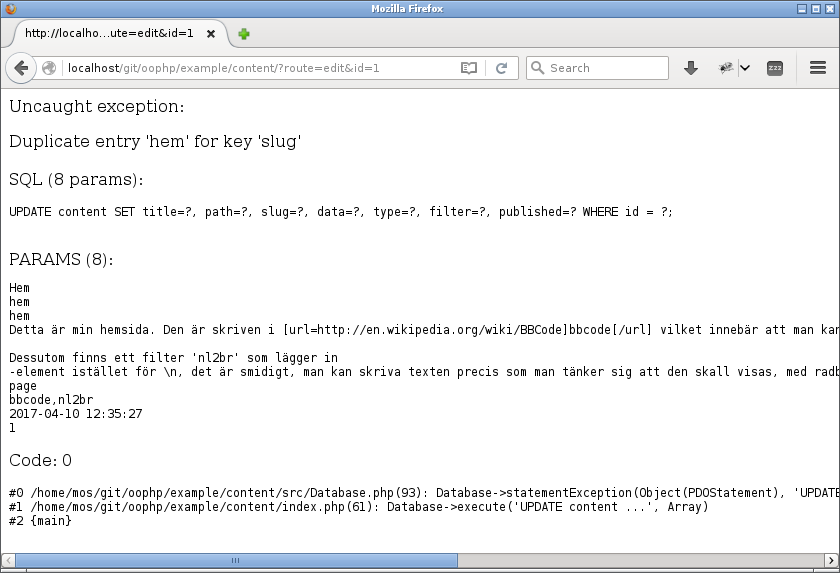
Det kan inte finnas två likadana slugs.
Här får man bygga in någon form av felhantering om man vill lösa detta bättre. Det lämnar vi som en övning till läsaren.
Man kan också fundera på om slugen skall vara unik, eller om den egentligen är unik i kombination med sin typ och kanske pathen. Det är något som man får bestämma sig hur, hur det skall fungera i just denna applikationen.
#Att lagra användarredigerat innehåll
En sak som kan vara på sin plats att nämna är strategin för att lagra informationen i databasen. Skall man sanitera den innan den lagras i databasen eller innan den används i webbsidan?
Jag väljer strategin att lagra innehållet precis som användaren skriver in det och sedan filtrera och sanitera när informationen skall visas i webbsidan. Jag föredrar att användaren kan spara ned precis vad som helst, men det ställer krav på att jag verkligen saniterar informationen och rensar bort skadlig kod, innan informationen skrivs ut.
Att låta användare skriva in vad som helst, utan att sanitera, har fördelen att användaren alltid känner igen texten som skrivs och det finns ingen magisk hantering som säger vilken text som är rätt eller fel. I mitt fall är det helt okey att skriva in både HTML-kod och PHP-kod, det som är viktigt är vilka filter man väljer att sätta på innehållet. Det är kombinationen av filter (och htmlentities()) som gör att texten saniteras och skadlig kod rensas bort.
Skillnaden mellan strategierna är när den skadliga koden rensas bort.
Det är också bra att kontrollera att inkommande variabler är definierade enligt den värdemängd som gäller.
$contentId = getPost("contentId") ?: getGet("id");
if (!is_numeric($contentId)) {
die("Not valid for content id.");
}
Innehåller inte inkommande variabler rätt värdemängd så kan man abrupt avbryta. Det är troligast att någon försöker manuellt redigera länkarna för att se om din webbplats har brister i säkerheten.
#Lägga till nytt innehåll
Då skapar vi funktionen för att lägga till nytt innehåll. Här får man tänkta till då alternativen är flera. Skall man lägga till en knapp eller en länk och var skall den finnas?
#Formulär och route för skapa
Jag väljer att lägga till en länk “Create” i menyn som leder till ett enkelt formulär där användaren får skriva in innehållets titel. När det formuläret postas så görs INSERT in i databasen och därefter en redirect till sidan där innehållet kan redigeras.
Tittar man på användargränssnittet så kan det se ut så här.
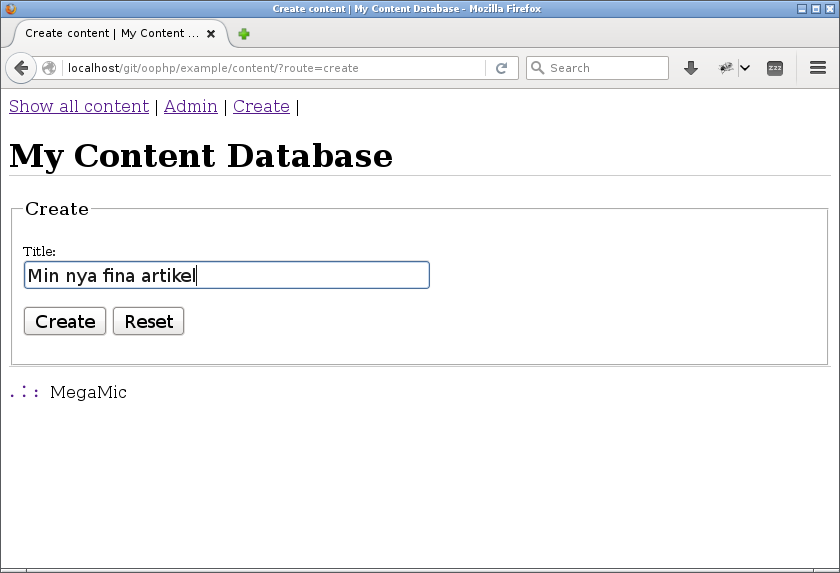
Ett minimalt formulär för att skapa en ny artikel.
När användaren klickar “Create” så skapas innehållet i databasen. Följande route tar hand om det.
case "create":
$title = "Create content";
$view[] = "view/create.php";
if (hasKeyPost("doCreate")) {
$title = getPost("contentTitle");
$sql = "INSERT INTO content (title) VALUES (?);";
$db->execute($sql, [$title]);
$id = $db->lastInsertId();
header("Location: ?route=edit&id=$id");
exit;
}
break;
Varken routen eller vyn innehåller särskilt mycket kod och jag är nöjd att kunna återanvända routen “edit” för att vidare redigera innehållet.
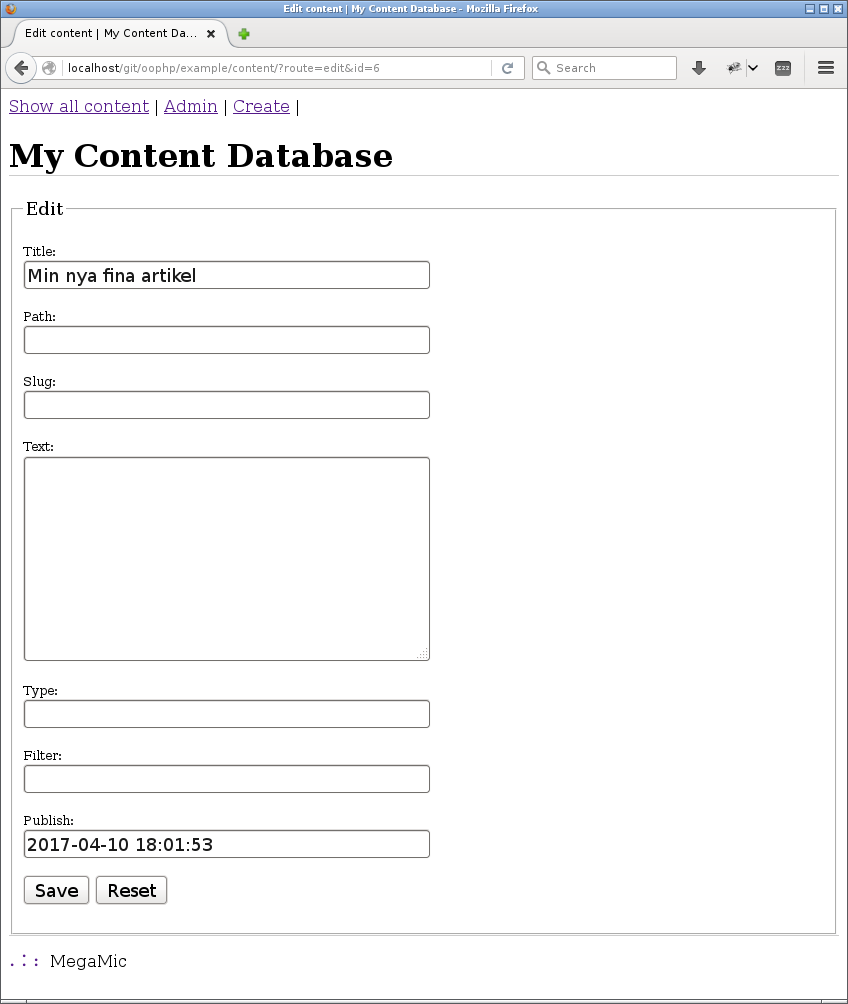
Det nyskapade innehållet finns nu i databasen och jag kan fylla på och spara dess värden.
Som du ser så är en nyskapad artikel redan publicerad. I mitt exempel är det bra eftersom jag slipper skriva in ett publiceringsdatum i formuläret. Men egentligen vill jag troligen inte att helt nyskapade artiklar skall vara publicerade. Det handlar om hur man väljer att sätta, eller inte sätta, defaultvärde på published.
#Tom sträng är inte samma sak som null
Var uppmärksam på att en tom sträng och NULL inte är samma sak i en databaskolumn. Att ha en path som är NULL är okey i databastabellen, även om det finns flera och trots att vi har satt UNIQUE på kolumnen. Men, det är inte okey att ha flera rader som har en path som är tomma strängen. Då får du fel, ungefär så här.
Duplicate entry ” for key ‘path’.
När du läser upp innehållet från databasen, lägger det i formuläret och åter sparar det, så är det lätt att ditt ursprungliga NULL görs om till en tom sträng. Om ett NULL-värde läggs i formuläret så postas det som en tom sträng.
Detta leder i sin tur till att du får problem med databastabellens restriktioner om att path skall vara UNIQUE. Ett enkelt sätt att gå runt problemet är att kontrollera om det postade fältet är tomt (tom sträng) och då sätta den till NULL istället, innan det sparas till databasen.
I sådana här fall är det bra att ha bra felhantering och det försöker vi har i vår klass Database som kastar Exception så fort något går fel.
När jag byggde mitt exempel så fick jag exakt detta problemet och jag löste det genom att sätta en tom path till null i min edit-sida.
if (!$params["contentPath"]) {
$params["contentPath"] = null;
}
Nu kan man sätta en “tom” path i formuläret och det sparas som NULL i databasen.
#Radera innehåll
Då har vi bara delete delen kvar i CRUD. Till att börja med så gör jag det enkelt och lägger till en knapp “Delete” i Edit-formuläret.
Sen tänker jag att det vore trevligt att kunna radera ett innehåll direkt från översikten i Admin via en delete-ikon.
Jag vill också ha en säkerhetsfråga “är du verkligen säker”, så att användaren inte av snabbhet eller misstag råkar radera ett innehåll.
Då ska vi se vilket användargränssnitt detta flöde kan få.
Först en ny knapp, nu med ikoner, i edit-formuläret.
Nu kan man radera ett innehåll från edit-formuläret.
Sedan en radera-ikon på översikten.
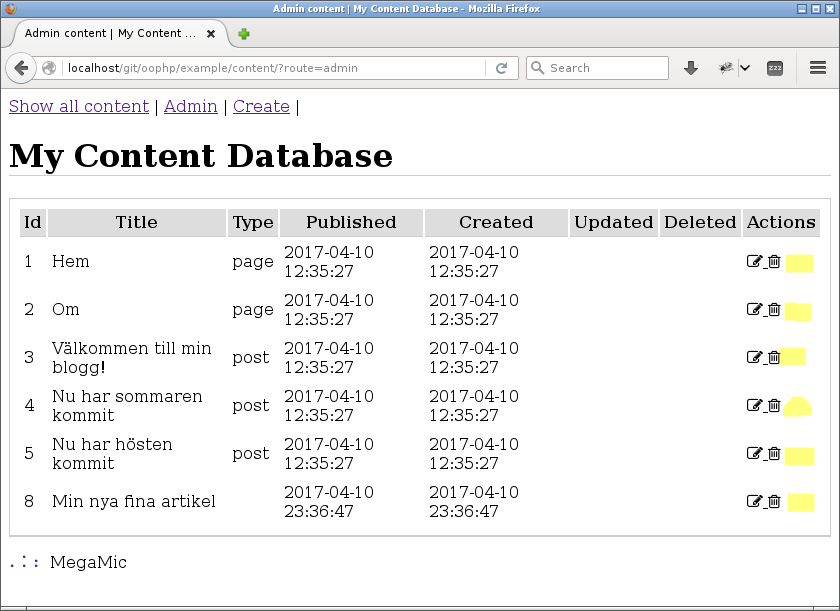
Det går även radera ett innehåll direkt från admin-vyn.
I båda fallen leder länken till en vy där man verkligen kan utföra raderingen. Allt för att undvika misstag.
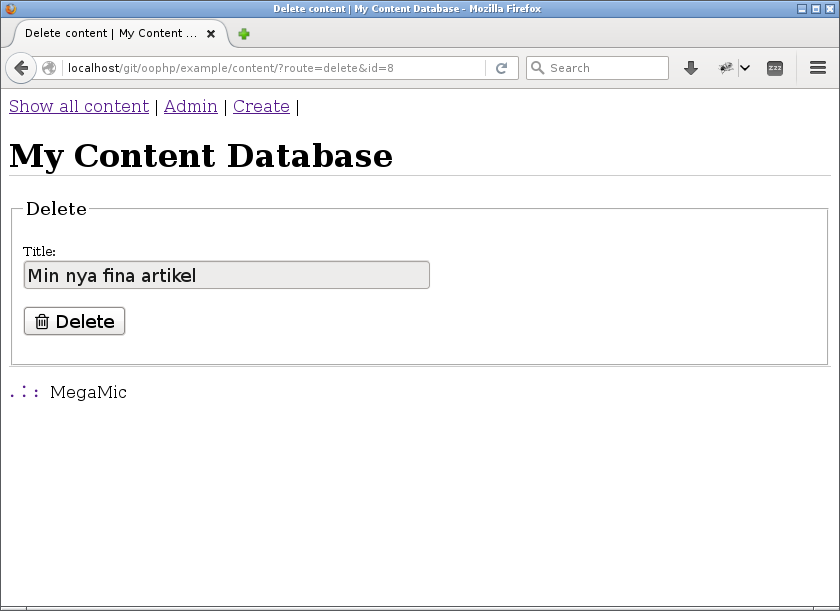
Nu kan vi verkligen radera innehållet.
Vyerna och formulärens förändringar är realtivt enkla för att skapa din readera-sida. Det som kan vara lite klurigt är hur man vill att flödet i applikationen skall fungera. Var kan kan radera och hur skall det gå till?
Vi tar en titt på routen som utför själva raderingen av innehållet.
case "delete":
$title = "Delete content";
$view[] = "view/delete.php";
$contentId = getPost("contentId") ?: getGet("id");
if (!is_numeric($contentId)) {
die("Not valid for content id.");
}
if (hasKeyPost("doDelete")) {
$contentId = getPost("contentId");
$sql = "UPDATE content SET deleted=NOW() WHERE id=?;";
$db->execute($sql, [$contentId]);
header("Location: ?route=admin");
exit;
}
$sql = "SELECT id, title FROM content WHERE id = ?;";
$content = $db->executeFetch($sql, [$contentId]);
break;
Notera att vi inte gör en riktig DELETE.
$sql = "DELETE FROM content WHERE id=?;";
Istället markerar vi innehållet som raderat, via en tidsstämpel som säger när innehållet raderades.
I övrigt så ser det mer eller mindre likadant ut som i de andra routerna. Liknande struktur och hantering. Det känns som vi börjar få koll på det här nu.
Vi kan avsluta med en kort titt på delete-vyn.
<form method="post">
<fieldset>
<legend>Delete</legend>
<input type="hidden" name="contentId" value="<?= esc($content->id) ?>"/>
<p>
<label>Title:<br>
<input type="text" name="contentTitle" value="<?= esc($content->title) ?>" readonly/>
</label>
</p>
<p>
<button type="submit" name="doDelete"><i class="fa fa-trash-o" aria-hidden="true"></i> Delete</button>
</p>
</fieldset>
</form>
Det man kan nämna är att innehållets id ligger i formuläret som postas för att raderas. Sedan skadar det inte att påpeka att göra htmlentites() på de värden som skrivs ut.
När ett innehåll är raderat så markeras det som raderat och det syns i admin-vyn.
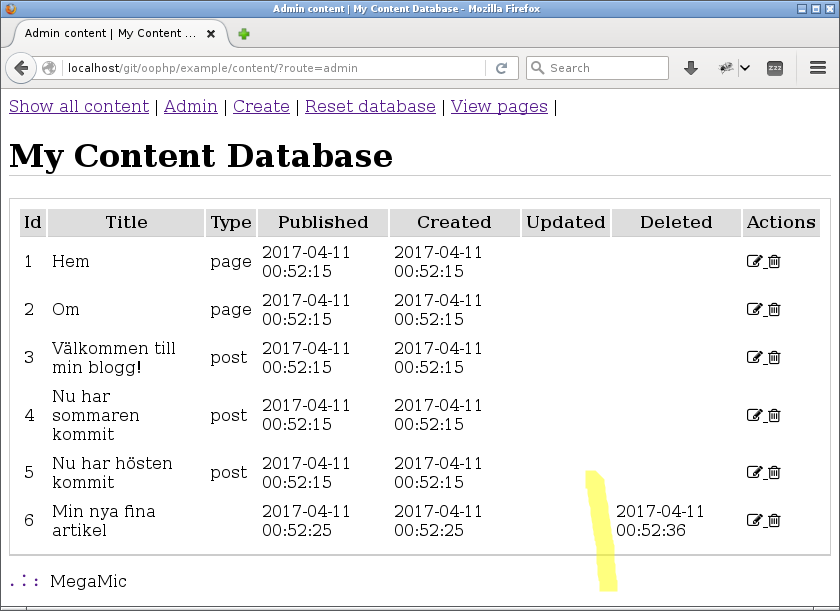
Artikeln som raderades är märkt som raderad, men inte fysiskt borttagen.
Nu hade vi kunnat lägga till en funktion som tar bort tidsstämpeln som anger när innehållet raderades. Då hade innehållet kommit tillbaka igen, som inget hade hänt. Det hade varit en form av papperskorg där vi kunde återhämtat innehåll vi raderat.
Nu är vi nöjda med CRUD-delen, det administrativa gränssnittet för att jobba med innehållet. Då fortsätter vi att se hur innehållet kan presenteras för användaren.
#Visa innehållet i webbplatsen
Då tar vi och visar upp innehållet från databasen i egna webbsidor. Tanken är att sidor av typen page skall visas upp som en egen webbsida och sidor av typen post visas som en blogg.
#Länkstrukturen
Här behöver vi en plan för hur länkningen skall ske. Min plan är så här.
Typen page kan nås via ?route=path där path mappas mot databaskolumnen path. Om man skapar en sida som har sin path satt till om så blir länken till sidan ?route=om.
Typen blog skall visa en blogglista på routen ?route=blog där blogginläggen kommer i ordning med senaste inlägget först. Vill man nå ett inlägg direkt och se hela inlägget som en egen sida, så är länken dit ?route=blog/slug där slug mappas mot databaskolumnen slug.
Om vi hade haft en riktig router så hade detta varit smidigt att sätta upp. I vår exempelkod med den hemmasnickrade varianten av router kan vi lösa det med en default hantering i switch-satsen. Grovt kan det se ut så här.
default:
if (substr($route, 0, 5) === "blog/") {
// Matches blog/slug, display content by slug and type post
} else {
// Try matching content for type page and its path
}
Det blev två olika varianter för default-hanteringen. Sen tillkommer att visa en översikt av blogginläggen på en egen sida (?route=blog), men det får bli en egen route.
#Visa innehåll av typ page via dess path
Vi börjar med en egen webbsida för innehåll av typen page. Här behöver vi söka ut det innehåll som är av typen page och där path matchar $route samt att innehållet är publicerat och inte raderat.
Fundera lite hur du hade löst det. Nu får vi använda våra SQL-kunskaper.
Snart kommer min variant, men först valde jag att bygga en översikt över de sidor som fanns. Det blir enklare att se och testa konstruktionerna samt enklare att klicka direkt till de sidor som kan visas. Om en sidan inte kan visas så får det bli en variant av 404.
Så här blev min översikt.
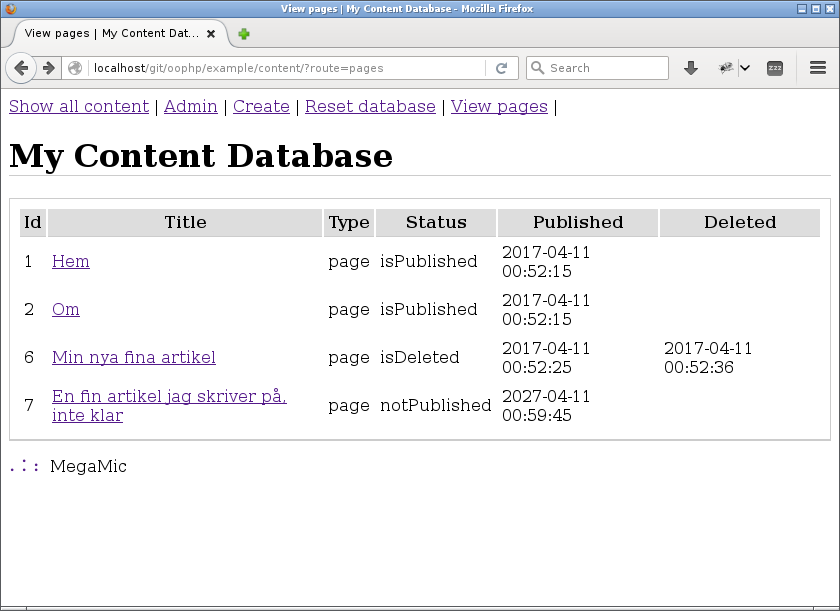
Här är en översikt av de webbsidor som är av typen page.
Du kan se att det visas vilken status sidan har, om den är publicerad eller inte och om den är raderad eller ej.
Låt oss kika på den route som bygger upp resultatet.
case "pages":
$title = "View pages";
$view[] = "view/pages.php";
$sql = <<<EOD
SELECT
*,
CASE
WHEN (deleted <= NOW()) THEN "isDeleted"
WHEN (published <= NOW()) THEN "isPublished"
ELSE "notPublished"
END AS status
FROM content
WHERE type=?
;
EOD;
$resultset = $db->executeFetchAll($sql, ["page"]);
break;
Själva routen följer samma struktur som tidigare, där hittar vi inget speciellt. Men kikar vi på SQL-frågan så har den ett inslag av en if-sats (CASE) som kollar status på kolumnerna deleted och published och därefter bestämmer vilken status innehållet har och lämnar svaret i den nyskapade kolumnen status.
Om jag nu klickar på länken till home så kan det se ut så här.
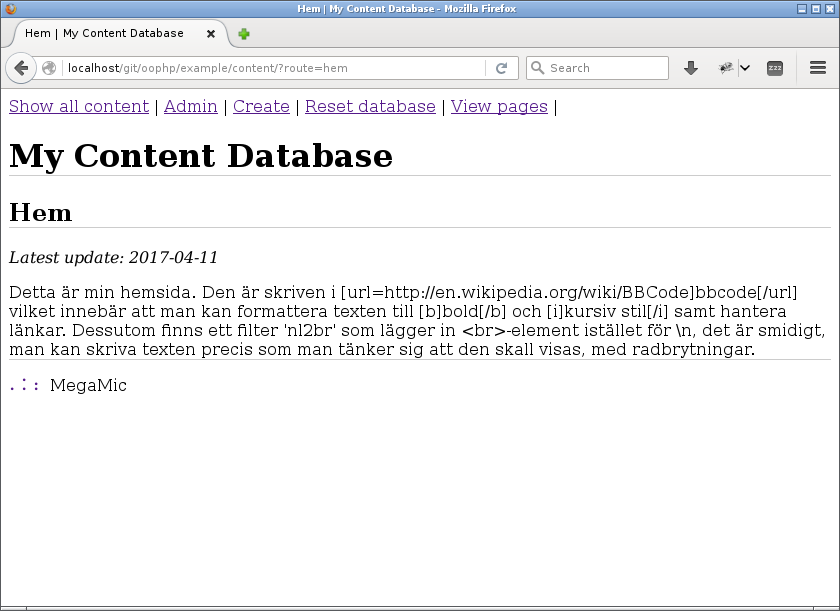
Sidan för home visas.
Ännu finns ingen formattering av texten, men innehållet visas som det ska.
Vi kan titta på vyn som är ansvarig för att visa upp resultatet.
<article>
<header>
<h1><?= esc($content->title) ?></h1>
<p><i>Latest update: <time datetime="<?= esc($content->modified_iso8601) ?>" pubdate><?= esc($content->modified) ?></time></i></p>
</header>
<?= esc($content->data) ?>
</article>
Det är inte så mycket kod men notera hur publikationsdatumet skrivs ut i två varianter, en läsbar för människor modified och en läsbar för maskiner modified_iso8601.
Att skapa de två datumen väljer jag att göra med SQL-koden. Vi kan titta på routen och dess SQL.
default:
if (substr($route, 0, 5) === "blog/") {
// Matches blog/slug, display content by slug and type post
} else {
// Try matching content for type page and its path
$sql = <<<EOD
SELECT
*,
DATE_FORMAT(COALESCE(updated, published), '%Y-%m-%dT%TZ') AS modified_iso8601,
DATE_FORMAT(COALESCE(updated, published), '%Y-%m-%d') AS modified
FROM content
WHERE
path = ?
AND type = ?
AND (deleted IS NULL OR deleted > NOW())
AND published <= NOW()
;
EOD;
$content = $db->executeFetch($sql, [$route, "page"]);
if (!$content) {
header("HTTP/1.0 404 Not Found");
$title = "404";
$view[] = "view/404.php";
break;
}
$title = $content->title;
$view[] = "view/page.php";
}
Själva SQL-frågan löser de två datumformaten där den väljer det första datumet av updated och published som inte är null som bas för modified.
I WHERE-delen så säkerställs att sidans path matchar, att det är rätt type och att den är publicerad och inte raderad, annars väljs den inte.
Om SQL-frågan ger ett tomt svar tillbaka så visas en 404-sida.
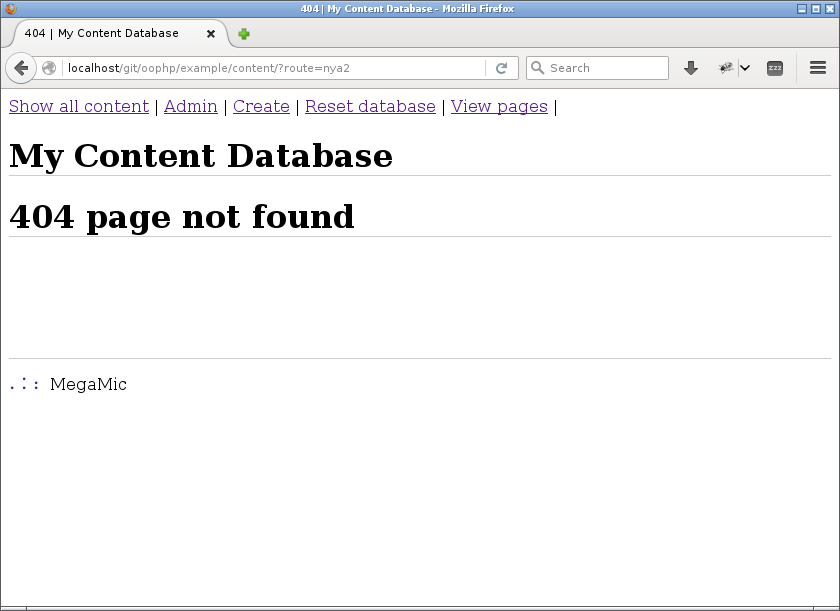
404 för att sidan kunde inte visas.
Ovan visas en sida som inte kunde visas för att den antingen inte fanns, den var raderad, eller var den ännu inte publicerad.
#Visa innehållet som blogg- och bloggposter
Då ger vi oss på att visa innehåll för bloggen vilket är allt innehåll av typen post. Grunden är densamma som för typen page, nu vill vi bara presentera resultatet mer som en blog.
Lite så här.
En blogglista med alla inlägg med senaste inlägget först.
Routen som förbereder visningen ser ut ungefär som visningen av sidorna (typen page). När man gjort grunderna så handlar det ibland bara om nyanser i skillnader i koden och utmaningen ligger i att skriva kod där man inte upprepar sig och koddelar kan återanvändas.
case "blog":
$title = "View blog";
$view[] = "view/blog.php";
$sql = <<<EOD
SELECT
*,
DATE_FORMAT(COALESCE(updated, published), '%Y-%m-%dT%TZ') AS published_iso8601,
DATE_FORMAT(COALESCE(updated, published), '%Y-%m-%d') AS published
FROM content
WHERE type=?
ORDER BY published DESC
;
EOD;
$resultset = $db->executeFetchAll($sql, ["post"]);
break;
Jag valde att jobba med publiseringsdatum, iallafall namngav jag kolumnen till published. I bloggsammanhang jobbar man ofta med ett publikationsdatum och ofta ändras eller uppdateras inte blogginlägget.
Vyn som listar inläggen är en kombination av de två vyerna som visade översikten av page samt dess innehåll.
<?php
if (!$resultset) {
return;
}
?>
<article>
<?php foreach ($resultset as $row) : ?>
<section>
<header>
<h1><a href="?route=blog/<?= esc($row->slug) ?>"><?= esc($row->title) ?></a></h1>
<p><i>Published: <time datetime="<?= esc($row->published_iso8601) ?>" pubdate><?= esc($row->published) ?></time></i></p>
</header>
<?= esc($row->data) ?>
</section>
<?php endforeach; ?>
</article>
Klickar man på länken till bloggposten så skall den visas på en egen sida. Det blir i stort sett samma hantering som för innehåll av typen page.
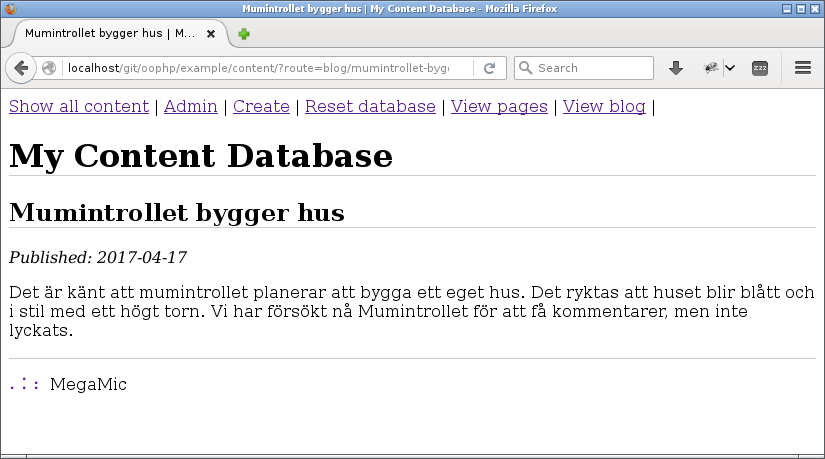
En bloggpost visas nästan på samma sätt som en page.
Routen delar grundstrukturen med den delen som visar typen page via dess path. Skillnaden ligger i SQL-frågan där slug används istället för path.
default:
if (substr($route, 0, 5) === "blog/") {
// Matches blog/slug, display content by slug and type post
$sql = <<<EOD
SELECT
*,
DATE_FORMAT(COALESCE(updated, published), '%Y-%m-%dT%TZ') AS published_iso8601,
DATE_FORMAT(COALESCE(updated, published), '%Y-%m-%d') AS published
FROM content
WHERE
slug = ?
AND type = ?
AND (deleted IS NULL OR deleted > NOW())
AND published <= NOW()
ORDER BY published DESC
;
EOD;
$slug = substr($route, 5);
$content = $db->executeFetch($sql, [$slug, "post"]);
if (!$content) {
header("HTTP/1.0 404 Not Found");
$title = "404";
$view[] = "view/404.php";
break;
}
$title = $content->title;
$view[] = "view/blogpost.php";
Men i övrigt ser det ut ungefär likadant. Det är en SQL-fråga som kollar om innehållet finns, om inte så visas en 404 och annars laddas en vy som visar innehållet i svaret.
Vi har nu innehållet i databasen, vi kan redigera det och presentera på olika sätt. Det som är kvar är att formattera utskriften.
#Formattering av texten
När användaren skriver in innehållet så är möjligheterna oändliga av hur innehållet kan formatteras. Vi lägger ingen direkt aspekt på hur innehållet skrivs in och vi lagrar det exakt på samma sätt i databasen. Men när det skrivs ut så skyddas det av ett anrop till esc() och htmlentities().
Tanken är nu att ge användaren ökad kontroll över hur innehållet formatteras innan det landar i webbsidan.
#Olika typer av filter
I mitt exempel har jag tänkt mig fyra olika textfilter som kan formattera texten enligt olika regler.
| Filter | Funktion |
|---|---|
| nl2br | Ersätt varje nyrad med en <br> för att ge enkel formattering av texten. PHP funktionen nl2br() utför jobbet. |
| bbcode | Formattering enligt bbcode är vanligt på forum och i kommentarsfält där användaren inte skall kunna skriva HTML-kod. En funktion med reguljära uttryck löser detta. |
| link | Gör länkar som skrivs i texten klickbara. Ett reguljärt uttryck gör jobbet. |
| markdown | Formattering enligt Markdown. Ett externt libb hjälper oss med Markdown. |
Coachen har skrivit en del artiklar om filtrering av text, bland annat “Reguljära uttryck i PHP ger BBCode formattering”, “Låt PHP-funktion make_clickable() automatiskt skapa klickbara länkar” samt “Skriv för webben med Markdown och formattera till HTML med PHP (v2)”. Dessa hjälper dig att göra en filterhantering till ditt innehåll.
Varje innehåll listar de filter som skall användas för att processa sidan, det är en komma-separerad lista av filter. Till exempel så här.
bbcode,nl2br
Ovanstående innebär att texten först filtreras enligt filtret för bbcode och därefter med filtret för nl2br.
Så är tanken. På det viset låter man användaren själv bestämma hur texten skall filtreras beroende på hur den är skriven och vad den skall användas till.
#Exempel på formattering
Om man tänker sig ett exempel som använder sig av ovan möjlighet till textformattering, så kan det se ut så här.
Först innehållet i sitt råa format, som det skrivs in av användaren.
$textOrig = <<<EOD
Först lite vanlig text följt av en tom rad.
Då tar vi ett nytt stycke med lite bbcode med [b]bold[/b] och [i]italic[/i] samt en [url=https://dbwebb.se]länk till dbwebb[/url].
Sen testar vi en länk till https://dbwebb.se som skall bli klickbar.
Avslutningsvis blir det en [länk skriven i markdown](https://dbwebb.se) och länken leder till dbwebb.
Avsluter med en lista som formatteras till ul/li med markdown.
* Item 1
* Item 2
EOD;
Sedan tänker vi oss att alla formatterings/filtreringsfunktioner är wrappade i en klass Textfilter och det finns en metod doFilter() som tar både texten och de filter som skall användas och returnerar den formatterade texten.
$textfilter = new Textfilter();
$text = $textfilter->doFilter($textOrig, "bbcode,markdown,link");
Den formatterade/filtrerade texten $textOrig skulle du kunna se ut så här.
<p>Först lite vanlig text följt av en tom rad.</p>
<p>Då tar vi ett nytt stycke med lite bbcode med <strong>bold</strong> och <em>italic</em> samt en <a href="https://dbwebb.se">länk till dbwebb</a>.</p>
<p>Sen testar vi en länk till <a href="https://dbwebb.se">https://dbwebb.se</a> som skall bli klickbar.</p>
<p>Avslutningsvis blir det en <a href="https://dbwebb.se">länk skriven i markdown</a> och länken leder till dbwebb.</p>
<p>Avsluter med en lista som formatteras till ul/li med markdown.</p>
<ul>
<li>Item 1</li>
<li>Item 2</li>
</ul>
Eller om man bygger ett exempel och gör ett litet testprogram av det, då kan resultatet bli så här.
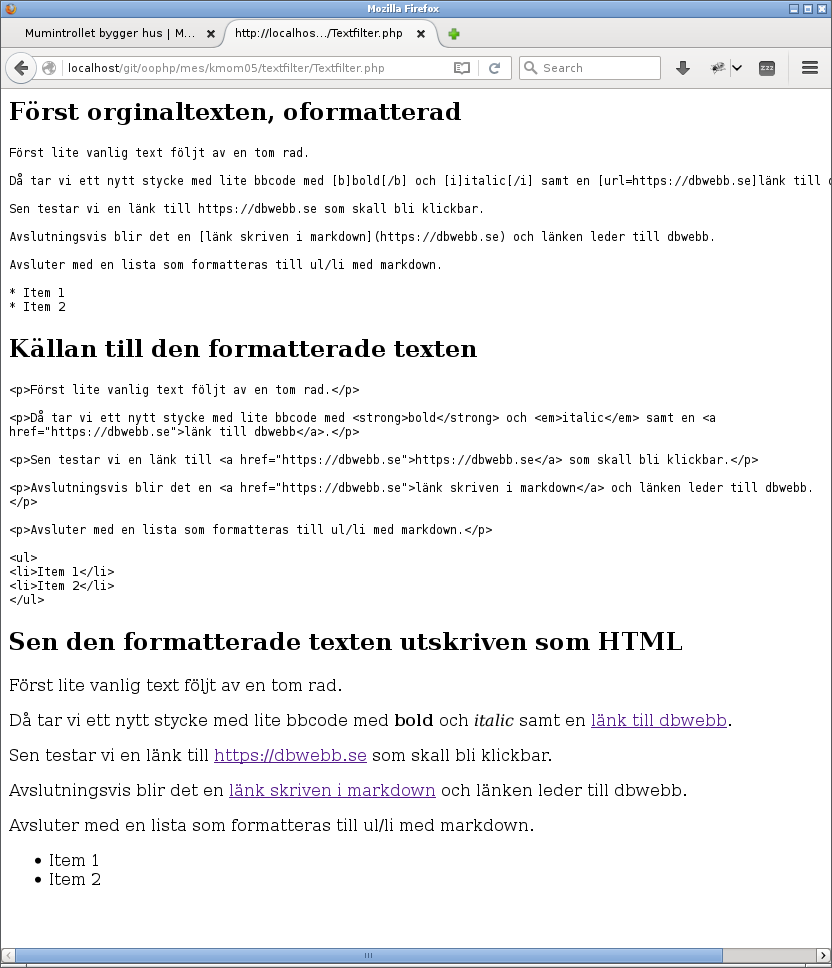
Innehållet formatteras och filtreras för att bli HTML.
Bilden ovan visar hur exemplet tar innehållets råa källa och formatterar det till HTML, först visas den råa formatterade HTML-koden och seda skrivs den ut så att webbläsaren får visa upp resultatet av HTML-koden.
#Tankar kring formatteringen
Hur kan man tänka kring säkerhet och vad det innebär att ge användaren denna typen av kontroll över innehållet?
Man får vara lite försiktig, om man inte filtrerar bort HTML-elementen med strip _tags() så har användaren fulla möjligheter att skriva både HTML och JavaScript rätt in i sidan. Men kanske vill man det. Det beror ju på hur väl man känner den som skriver texten. Här får man välja taktik.
Det finns tillfällen då jag själv uppskattat möjligheten att skriva PHP-kod rätt in i sådant innehåll som vi nu sett. Det rörde sig om ramverk som annars krävde större energi för att lösa ett krav på alternativt sätt. Men en sådan möjlighet öppnar naturligtvis hela din server för den som kan redigera innehållet.
Man får även tänka på att vissa filter inte är kompatibla med varandra eller att ordningen av filtren är viktig. Om man till exempel använde nl2br innan ett markdown så kan det första filtret förstöra för det andra. Kanske borde man styra vilka kombinationer av filter som är tillgängliga, eller så ger man all makt till användaren.
Det finns inget färdigt exempel för klassen Textfilter, det lämnas som en programmeringsövning till läsaren.
#Avslutningsvis
Artikeln visar översiktligt i hur du kan bygga upp en databas för att lagra och CRUD-hantera innehåll i databasen samt tekniker för att presentera det i webbplatsen som olika typer av innehåll.
Det finns en tråd i forumet där du kan ställa frågor eller bidra med tips och trix rörande artikeln.
#Revision history
- 2018-05-09: (F, mos) lade till video intro.
- 2018-04-30: (E, mos) Genomgången inför oophp-v4.
- 2017-04-18: (D, mos) Uppdaterad till nya version inför oophp-v3.
- 2014-10-20: (C, mos) Bytte koden till doFilter(), innehöll fel.
- 2013-12-03: (B, mos) Smärre justeringar inför campus-kursen.
- 2013-09-30: (A, mos) Första utgåvan i samband oophp-kursen.
