


Hur fungerar det?
För att enklare hänga med i guiden behöver vi förstå hur verktyget jobbar och hur vi arbetar med det. Först och främst behöver vi få reda på hur datan behandlas.
#Arbetsflöde
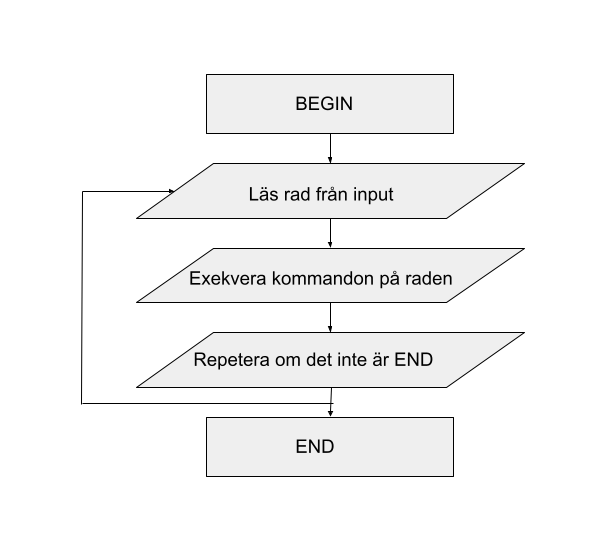
Exekveringsflöde av ett awk kommando
Arbetsflödet kan beskrivas som Läsa -> Exekvera -> Repetera. Awk läser en rad från den sk “input strömmen”. Det kan vara från en fil, ett kommando eller input från terminalen (stdin). Sedan körs alla awk kommandon på alla rader. Vi kan styra vilka rader som ska användas. Vi tittar på det lite senare. Detta repeteras sedan till raderna/filen tar slut.
Awk läser som sagt in datan (inputen) rad för rad. Varje rad kallas för record. Varje rad delas sedan upp i bitar kallade fields.
Datan delas upp med hjälp av record separators (RS) och field separators (FS). Om vi inte sätter dem själva är defaultläget: RS=”\n” och FS=” “. RS är nyrad och FS är ett mellanslag.
#Programmets struktur
Strukturen är uppdelad i framförallt tre block:
BEGIN { kommandon }
/pattern/ { kommandon }
END { kommandon }
Det är valfritt att använda sig av ett “pattern” (regujära uttryck). Det kommer vi ta upp senare i guiden. BEGIN blocket körs en gång innan BODY exekveras. Notera att BODY inte har ett keyword, utan enbart måsvingarna. BODY körs sedan på alla rader och till slut, efter alla rader har processats körs END blocket. Både BEGIN och END är optionella.
#Olika sätt att jobba med awk
För mindre processering kan vi köra hela kommandot på kommandoraden. När vi behöver lite mer bearbetning av datan kan vi med fördel lägga in stora delar av kommandot i en scriptfil som vi exekverar. Vi ska kika på båda varianterna i den här guiden.
Som en duktig programmerare så tar vi såklart en titt i manualen:
$ man awk
Vi kommer inte gå igenom hela manualen, utan skrapa lite på ytan. Notera dock att den finns och använd den som referensmaterial.
#Revision history
- 2020-02-10: (A, lew) Första versionen.