


How does it work?
To make it easier to keep up with the guide, we need to understand how the tool works and how we work with it. First of all, we need to find out how the data is processed.
#Workflow
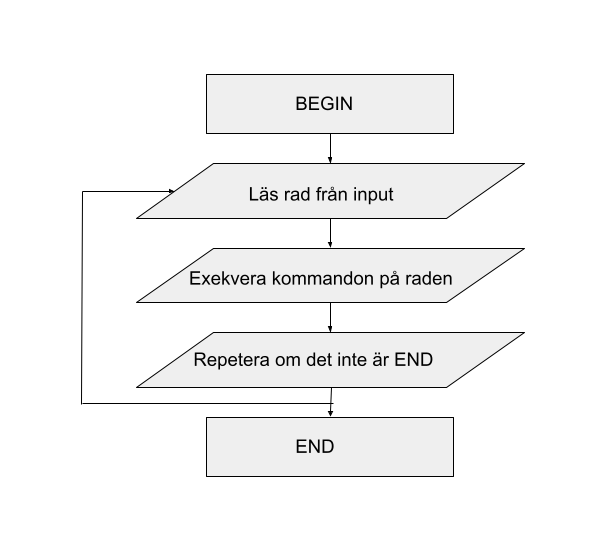
Workflow of an awk command
The workflow can be described as Read -> Execute -> Repeat. Awk reads a row from the “input stream”. It can come from a file, a command or input from the terminal (stdin). Then all awk commands are run on all lines. We can control which lines to use. We’ll look at that a little later. This is then repeated until the lines / file run out.
Awk reads in the data (input) line by line. Each line is called a record. Each row is then divided into pieces called fields.
The data is divided with record separators (RS) and field separators (FS). If we do not manually set them, the default behaviour is: RS=”\n” och FS=” “. RS is new row and FS is a space.
#Program structure
The structure is divided in three blocks:
BEGIN { commands }
/pattern/ { commands }
END { commands }
It is optional to use a “pattern” (regular expression). We will address this later in the guide. The BEGIN block is run once before BODY is executed. Note that BODY does not have a keyword, only the curly brackets. BODY is then run on all lines and finally, after all lines have been processed, the END block is run. Both BEGIN and END are optional.
#Different ways to work with awk
For less processing, we can run the entire command on the command line. When we need a little more processing of the data, we can advantageously put large parts of the command in a script file that we execute. We will look at both variants in this guide.
As a good programmer, we of course take a look at the manual:
$ man awk
We will not go through the entire manual, but scratch the surface a bit. Note, however, that it exists and use it as a reference material.
#Revision history
- 2021-06-29: (A, lew) Translated to english.