

Kokbok för databasmodellering
eller Entity-relationship-modellering (ER-modellering)
Detta dokument handlar om modellering av databaser. Vi delar in modelleringen i tre olika faser med olika syften att fylla. Vi skapar sedan en enkel process i 10-steg som steg för steg hjälper oss att modellera små som stora databaser.
Små databaser modelleras i utvecklarens huvud och dokumenteras i SQL-kod. Större databaser modelleras baserat på en verksamhetsanalys. En verksamhetsanalys som är resultatet av en diskussion mellan flera grupper av individer, både utvecklare och icke-tekniska personer.
Läs dokumentet och använd de delar du anser passa i ditt specifika projekt.
#Inspelad föreläsning
Det finns en inspelad föreläsning som grundar sig på information i denna artikeln. Se den gärna som ett komplement till att läsa artikeln.
Det finns också ytterligare två föreläsningar som hanterar artikelns innehåll och modellering av databaser.
- “ER modellering - konceptuell modellering (med Mikael) (24 min)”
- “ER-modellering - översätt till relationsmodellen aka Logisk modellering (med Mikael) (26 min)”
Du finner dessa föreläsningar längst ned i artikeln.
#Databasmodellering i tre faser
#De olika faserna
När vi jobbar med att designa databasen så gör vi det i tre olika modelleringssteg, dessa steg kallar vi konceptuell modellering, logisk modellering och fysisk modellering.
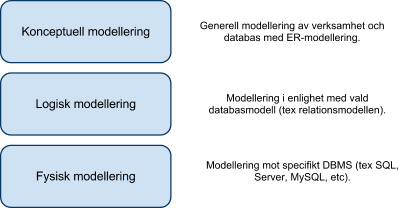
Översikt av de olika modelleringsfaserna.
I den konceptuella fasen så gör vi en generell databasmodell utan tanke på vilken databasmodell vi skall använda. I den logiska fasen så har vi bestämt oss för en relationsdatabas. I den fysiska fasen så har vi bestämt vilken databas/DBMS (SQL Server, MySQL, etc) vi skall använda.
#Konceptuell modellering
Konceptuell modellering, eller konceptuell design; här beskriver vi databasen, med text och genom att rita ER-diagram (Entity-Relationship eller Entitet-Relation). I detta steget vill vi att icke-tekniska personer skall kunna förstå och diskutera vår modell. Vi behöver en ritning och ett gemensamt språk som både vi tekniker och de som kan verksamheten förstår. Detta gör att vi kan få tidig feedback på att vi är på rätt spår och att vi bygger rätt system.
#Logisk modellering
Logisk modellering, eller logisk design; den konceptuella modellen översätts till en logisk modell som går att lagra i en databas. Vi jobbar med relationsdatabaser och vi översätter till en logisk modell som fungerar enligt relationsmodellen. Om vi hade jobbat med objektorienterade databaser hade vår logiska modell fått ett annat utseende. Ett utseende som hade stött den objektorienterade modellen. När vi är klara med den logiska modelleringen så har vi databasens schema, vi vet vilka tabeller som databasen skall innehålla.
Övergången mellan den konceptuella modelleringen och den logiska modelleringen är lite flytande. Ju mer erfaren man blir desto mer hänsyn tar man till relationsmodellen, eller den objektorienterade modellen, redan i den konceptuella modelleringen. Principen är dock att vi inte behöver binda oss vid någon datalagringsmodell när vi befinner oss i det konceptuella modelleringsstadiet. Där är det istället viktigare att kunna prata samma språk som kunden och kundens representanter.
#Fysisk modellering
Fysisk modellering, eller fysisk design; det är nu dags att skapa tabellerna, i detalj bestämma hur de skall se ut och vilka datatyper attributen skall ha. I detta steget så vet vi vilken databashanterare vi skall använda och vi kan då skräddarsy vår databas till den. Vi ser över vilka fysiska lagringsstrukturer vi skall ha och vi ser över användning av index och överväger möjligheter att införa nya tabeller av prestandaskäl.
Skillnaden mellan logisk modellering och fysisk modellering är framförallt att vi i den fysiska modelleringen har bestämt vilken databashanterare som skall användas. Tanken är att man inte behöver binda sig vid en viss databashanterare under den logiska modelleringen. Just valet av databashanterare kan ställa olika krav på hur själva databasen implementeras och används. Det ställer i sin tur krav på databasens schema, hur vi väljer att lagra datat i tabeller. I den fysiska modelleringen så kan vi ta hänsyn till prestanda som i sin tur kan påverka hur vi väljer att lagra datat.
Det sista vi gör, i modelleringen, är att lista de transaktioner som databasen skall stödja. Låt oss kalla det att skapa ett API, ett interface till databasen. Detta interface består av de transaktioner som databasen skall stödja. Det handlar om att lägga till, ta bort och uppdatera datat i databasen samt söka ut värden och förbereda dem för presentation. Ofta används databasen från ett eller flera applikationsprogram och det gynnar oss att skapa ett rent interface mellan databasen och applikationsprogrammen.
När vi listar transaktionerna så märker vi ibland vi att små förändringar av tabeller, eller tillägg av attribut och tabeller, är nödvändiga för att enkelt kunna jobba med databasen. Detta innebär att databasens schema, tabellerna och deras struktur, kan påverkas även i detta modelleringssteg.
#Summering
Summa summarum, tre olika steg, eller faser, för att att modellera en databas enligt alla konstens regler. Om vi redan från början vet att vi jobbar med en relationsdatabasen (tex SQL Server eller MySQL) så är det naturligt att hela modellerandet påverkas redan i den konceptuella fasen. Likadant gäller att om det är en enklare databas, få personer inblandade, så finns ingen anledning att krångla till det. Ju mer och mer vi kan desto fortare hoppar vi direkt på tabellernas struktur och listar dess transaktioner. Men, principiellt så är det bra att tänka sig modellering enligt stegen ovan och det brukar inte bli krångligare bara för att man gör det stegvis.
#Tio steg för att modellera din databas
Låt oss göra en liten 10-stegs kokbok som i 10 steg leder oss till en modellerad databas enligt de tre stegen (konceptuell, logisk, fysisk). Denna lilla 10-stegs raket hjälper oss att modellera små som stora databaser.
#Översikt av kokbokens 10 steg
| Steg | Modelleringsfas | Vad? |
|---|---|---|
| 1 | Konceptuell | Beskriv databasen i ett textstycke. |
| 2 | = | Skriv ned alla entiteter. |
| 3 | = | Skriv ned alla relationer och visa i matris. |
| 4 | = | Rita enkelt ER-diagram med entiteter och relationer. |
| 5 | = | Komplettera ER-diagram med kardinalitet. |
| 6 | = | Komplettera ER-diagram med alla attribut samt kandidatnycklar. |
| 7 | Logisk | Modifiera ER-diagram enligt relationsmodellen. |
| 8 | = | Utöka ER-diagram med primära/främmande nycklar samt kompletterande attribut. |
| 9 | Fysisk | Skapa SQL DDL för tabellerna. |
| 10 | = | Lista funktioner som databasen skall stödja (API). |
I den konceptuella fasen så gör vi en generell databasmodell utan tanke på vilken databasmodell vi skall använda. I den logiska fasen så har vi bestämt oss för en relationsdatabas. I den fysiska fasen så har vi bestämt vilken databas/DBMS (SQL Server, MySQL, etc) vi skall använda.
#Konceptuell modellering
Under den konceptuella modelleringen så är det viktigt att icke-tekniska personer kan förstå och ta del av vårt modellerande. Därför använder vi vanlig text och vi ritar ER-diagrammet på ett sätt som är lättförståeligt, även för de som inte har tekniskt kunnande.
#1. Beskriv databasen i ett textstycke
Använd löpande text för att beskriva databasen, vad som skall lagras och hur den skall användas.
“Vi skall utveckla ett webbaserat system för presentation av filmer. Filmerna skall presenteras tillsammans med information och bilder av innehållet och skådespelarna.
Filmerna är indelade i kategorier (komedi, action, drama, mfl) och för varje film finns information lagrad (titel, regissör, handling, bilder, skådespelare). Det kan finnas flera bilder och skådespelare för varje film.
Skådespelarna presenteras tillsammans med information (namn, ålder, bilder, biografi) och för varje skådespelare finns en lista med vilka filmer de deltagit i (filmografi). Systemets användare kan betygssätta varje film och kommentera betyget (hur bra/dålig filmen var…).”
Ibland får vi denna text som ett resultat från en verksamhetsanalys och ibland skriver vi den själva. Om vi skriver den själva så är det bra att redan på detta stadiet formulera sig och peka på de delar som skall lagras i databasen.
Viktigt är att formulera målet med databasapplikationen, vad är det som databasen skall lösa? Senare i vårt modellerande, är det bra att kunna gå tillbaka och peka på målet, det är målet som är viktigt! Annars är risken att man svävar ut och modellerar sånt som inte är relevant för att lösa den ursprungliga uppgiften. Vilken i sin tur genererar onödigt arbete för innehåll som ingen vill ha. I vår text så är målbeskrivningen följande:
“Vi skall utveckla ett webbaserat system för presentation av filmer. Filmerna skall presenteras tillsammans med information och bilder av innehållet och skådespelarna.”
#2. Skriv ned alla entiteter
Entiteter är substantiv som är kandidater till lagring i databasen. Börja med att stryka under alla kandidater och skriv slutligen ned dem i en lista. Dessa entiteter blir ofta tabeller i databasen.
“Vi skall utveckla ett webbaserat system för presentation av filmer. Filmerna skall presenteras tillsammans med information och bilder av innehållet och skådespelarna.
Filmerna är indelade i kategorier (komedi, action, drama, mfl) och för varje film finns information lagrad (titel, regissör, handling, bilder, skådespelare). Det kan finnas flera bilder och skådespelare för varje film.
Skådespelarna presenteras tillsammans med information (namn, ålder, bilder, biografi) och för varje skådespelare finns en lista med vilka filmer de deltagit i (filmografi). Det skall gå att betygssätta varje film och kommentera betyget (hur bra/dålig filmen var…).”
När vi väl hittat alla entiteter så skriver vi ned dem i en lista.
- Film
- Kategori
- Bild
- Skådespelare
- Betyg
Ofta hittar vi flera kandidater och då får vi fundera på vad som är rimligt och inte. Gå tillbaka till målbeskrivningen om du behöver vägledning.
#3. Skriv ned alla relationer och visa i en matris
Låt oss fortsätta med att skriva ned alla relationer som är av intresse. Relationer är verben som binder entiteterna samman. Det finns normalt flera kandidater till relationer men vi tar bara med de som vi anser vara relevanta för uppgiften.
- Alla filmer är kategoriserade enligt en kategori.
- Varje film illustreras av ett antal bilder.
- Varje film har ett antal skådespelare.
- Film har ett antal betyg.
- Skådespelare presenteras med bilder.
För att få en bra översikt över entiteterna och dess relationer så kan vi skapa en matris enligt följande.
| Entiteter | Film | Kategori | Bild | Skådespelare | Betyg | |
|---|---|---|---|---|---|---|
| Film | är kategoriserade enligt | illustreras av | har | har | ||
| Kategori | ||||||
| Bild | ||||||
| Skådespelare | har | |||||
| Betyg |
Relationerna går ju åt båda hållen men vi försöker förenkla genom att endast ta med det mest relevanta hållet. Excel är ett bra verktyg att använda för att skapa en sådan här matris, eller i en vanlig tabell i en ordbehandlare.
#4. Rita ett ER-diagram med entiteter och relationer
Låt oss nu rita vår första variant av ER-diagrammet. Vilket ritverktyg som helst funkar, även papper och penna. Jag använder Keynote (Apples variant av Powerpoint) för att rita nedanstående bilder.
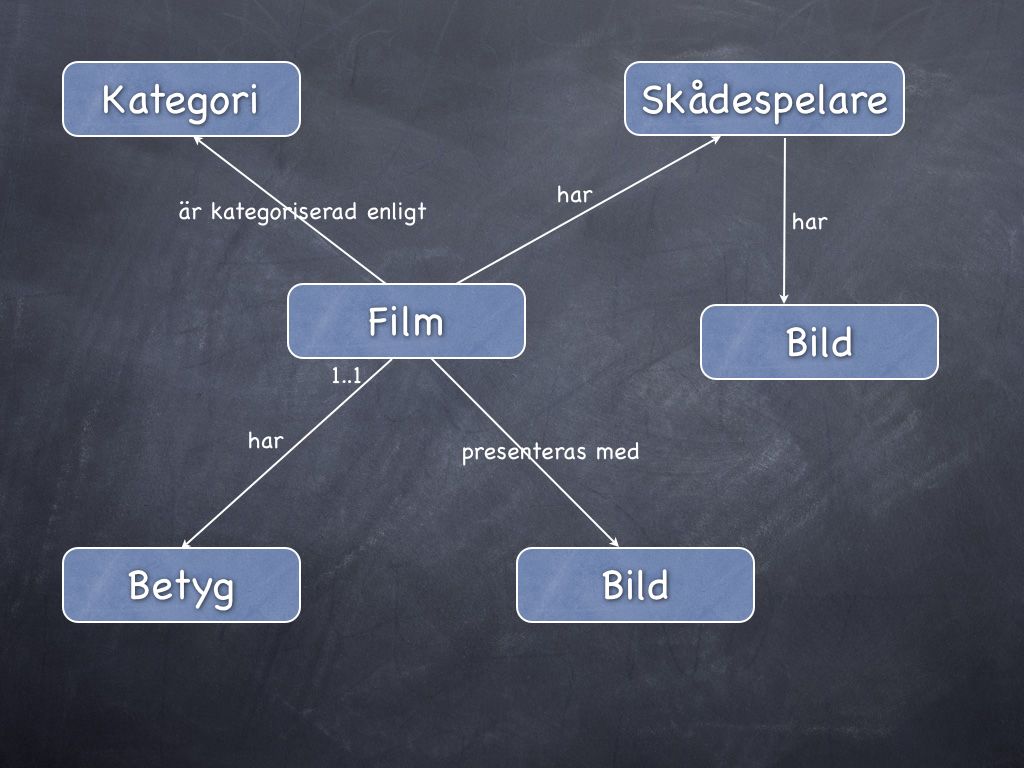
ER-diagram med entiteter och relationer.
Ok, inget konstigt va? Möjligen bortsett från att vi har två instanser av Bild, men vi låter det vara så tills vidare.
#5. Komplettera ER-diagrammet med kardinalitet
Låt oss uppdatera vårt ER-diagram och rita in kardinaliteten på relationerna.
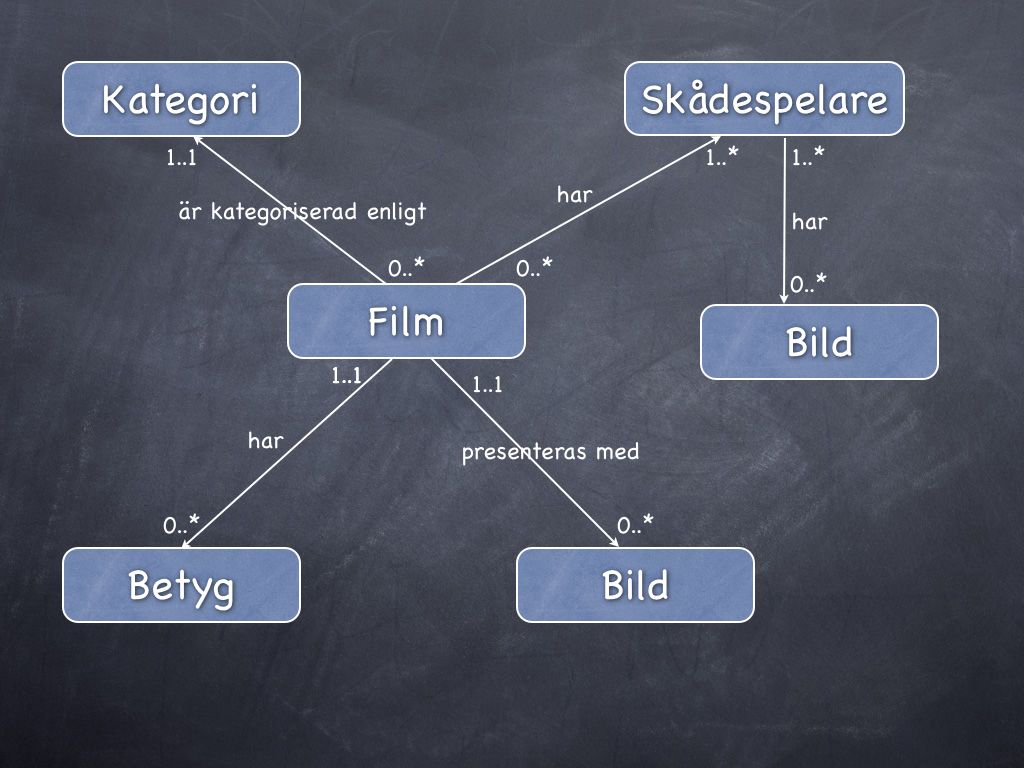
ER-diagram kompletterat med kardinalitet.
I ER-diagrammet ovan kan vi uttyda följande kardinaliteter:
En film är alltid kategoriserad enligt en kategori och en viss kategori kan vara kopplad till en eller flera filmer.
En film kan ha ett eller flera betyg och varje betyg är kopplat till en specifik film.
Varje film har 1 eller flera skådespelare och varje skådespelare kan finnas i 0 eller flera filmer.
Varje film presenteras med 0 eller flera bilder och varje bild är kopplad till en film.
Varje skådespelare har 0 eller flera bilder och varje bild är kopplad till en eller flera skådespelare.
Vi kan därmed att vi har följande typer av relationer baserat på deras kardinalitet.
| Relation | Typ |
|---|---|
| Film - Kategori | 1:1 |
| Film - Betyg | 1:N |
| Film - Bild | 1:N |
| Film - Skådespelare | N:M |
| Skådespelare - Bild | N:M |
#6. Komplettera ER-diagrammet med attribut och kandidatnycklar
Vi uppdaterar ER-diagrammet med attribut och vi drar ett streck under det/de attribut som är vår potentiella kandidat till nyckel. Vi utgår från texten i steg1 för att finna attributen.
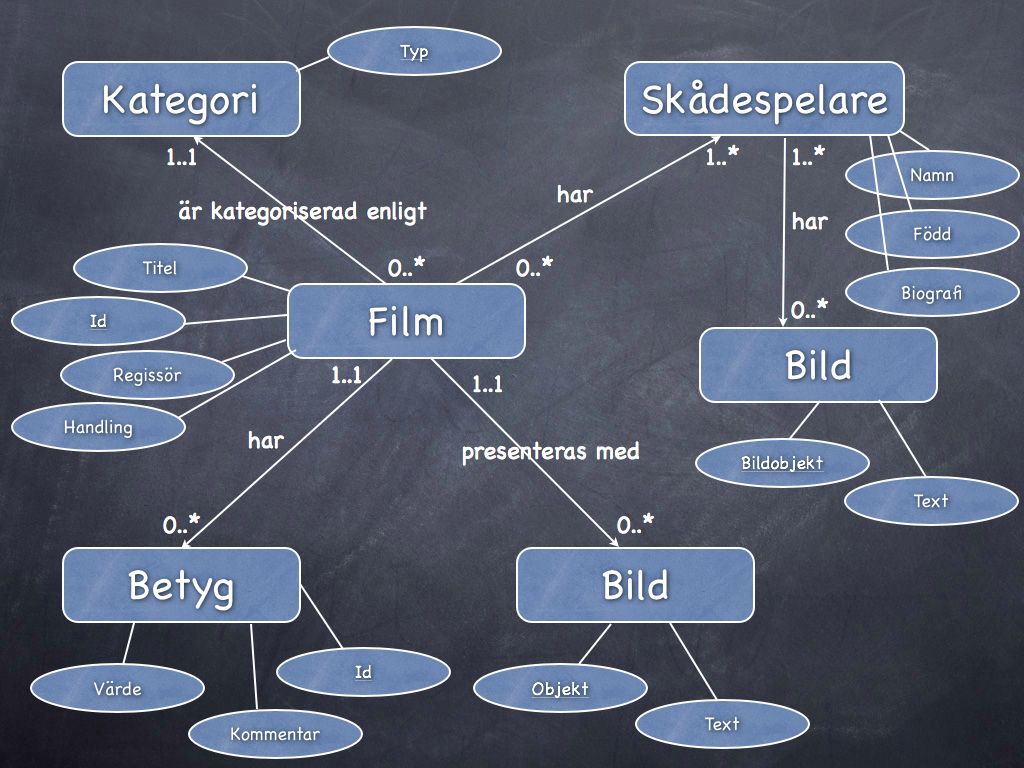
ER-diagram med attribut och kandidatnycklar.
Nu börjar det forma sig. I ren text skulle vi kunna beskriva ovanstående bild så här.
- Film (id, titel, regissor, handling)
- Kategori (typ)
- Bild (objekt, text)
- Skådespelare (namn, fodd, biografi)
- Betyg (id, varde, kommentar)
#Logisk modellering
När vi går över till den logiska modelleringen så vet vi att det är en relationsdatabas vi skall använda. Då känns det passande att rita om ER-diagrammet så att det liknar de tabeller vi skall lagra. I denna fas så gäller det att likasinnade programutvecklare kan förstå vårt ER-diagram.
#7. Modifiera ER-diagrammet enligt relationsmodellen
Vi gör en första ansats att modifiera ER-diagrammet så att det passar relationsmodellen. Framförallt har vi ett par N:M-förhållanden (många-till-många) att dela upp.
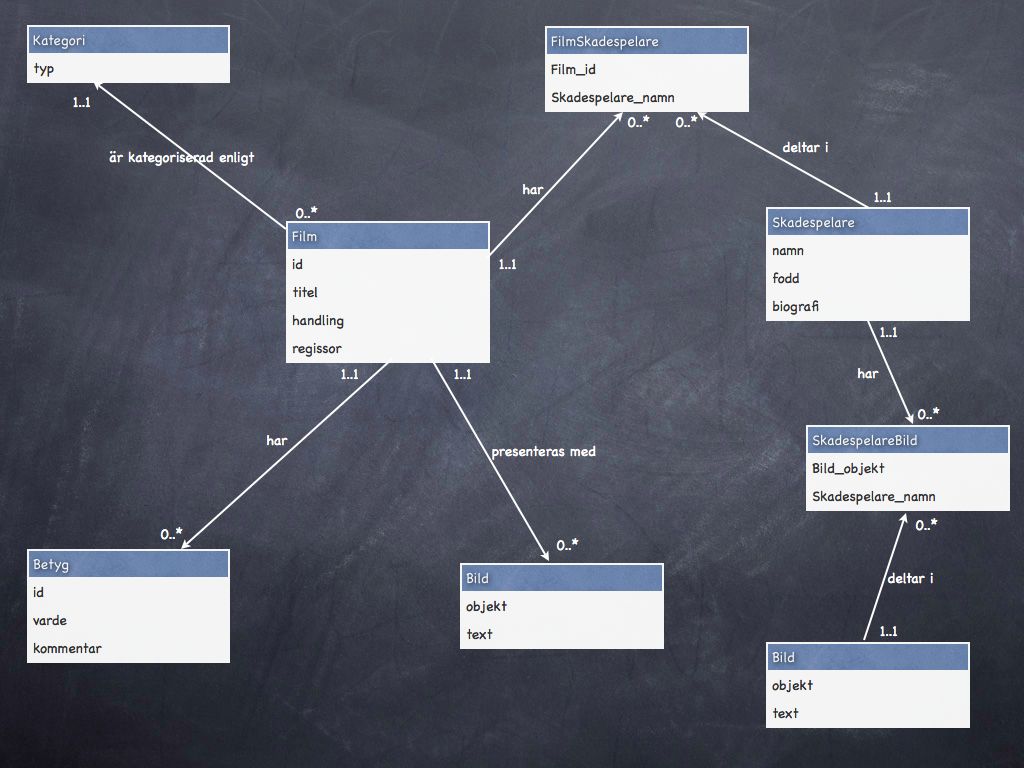
ER-diagram med attribut och kandidatnycklar.
Vi måste se till att vår modell stämmer överens med bla följande:
- Inga många-många förhållanden (N:M).
- Inga flervärdesattribut.
- Endast ett värde i varje cell.
- Varje rad är unik.
- Inga komplexa relationer.
En text-mässig beskrivning av det uppdaterade ER-diagrammet kan se ut så här.
- Film (id, titel, regissor, handling)
- Kategori (typ)
- Bild (objekt, text)
- Skådespelare (namn, fodd, biografi)
- FilmSkadespelare (Film_id, Skadespelare_namn)
- SkadespelareBild (Bild_objekt, Skadespelare_namn)
- Betyg (id, varde, kommentar)
#8. Utöka ER-diagrammet med primära och främmande nycklar samt kompletterande attribut
Vi ser över ER-diagrammet en gång till och kompletterar med nycklar och attribut. Understrukna och gråmarkerade attribut får representera primärnyckel och en brädgård (#) får representera främmande nyckel. Ibland får vi komplettera modellen med ytterligare attribut, t.ex. id-attribut kan ibland vara bra att ha såsom ett automatgenererande id som gör varje rad unik. Ibland krävs det även att vi gör ytterligare tabeller.
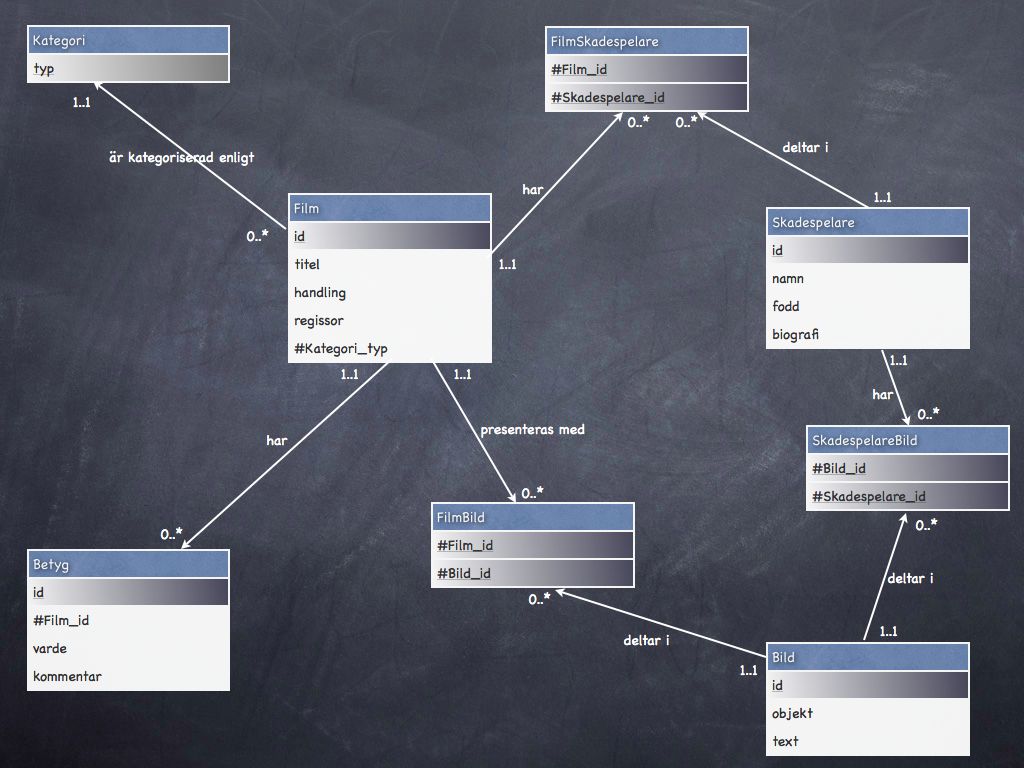
ER-diagram med primära och främmande nycklar.
I varje steg av vårt modellerande måste vi ta olika beslut, det finns ofta flera alternativ att beakta. Försök alltid hålla dig till det ursprungliga målet med databasen, det kan underlätta. Om man är osäker så är det ofta inget problem, oavsett hur du modellerar i detta steget så kan du alltid gå tillbaka och ändra modellen i ett senare steg. Ofta lär man sig mer och mer om sin databas ju mer man använder den.
En beskrivning i text av vårt diagram kan se ut som följer.
Film (id, titel, regissor, handling, #Kategori_typ)
FilmBild (#Film_id, #Bild_id)
Kategori (typ)
Bild (id, objekt, text)
Skådespelare (id, namn, fodd, biografi)
FilmSkadespelare (#Film_id, #Skadespelare_id)
SkadespelareBild (#Bild_id, #Skadespelare_id)
Betyg (id, #Film_id, varde, kommentar)
#Fysisk modellering
Det är du dags att skapa SQL DDL för vår databas. Vi väljer datatyper för attributen, funderar på index och prestanda.
#9. Skapa SQL DDL för tabellerna
För vår modell skulle en enkel SQL DDL, för en delmängd av tabellerna, se ut som följer.
CREATE TABLE Film
(
id INT,
titel CHAR(100),
regissor CHAR(100),
handling VARCHAR(400),
Kategori_typ CHAR(10)
);
CREATE TABLE FilmBild
(
Film_id INT,
Bild_id INT
);
CREATE TABLE Kategori
(
typ CHAR(10)
);
Innan den blir helt färdig måste vi komplettera den med primärnycklar och främmande nycklar. En uppdaterad SQL DDL, inklusive nyckeldefinitioner, kan se ut här.
CREATE TABLE Film
(
id INT PRIMARY KEY NOT NULL,
titel CHAR(100) NOT NULL,
regissor CHAR(100) NOT NULL,
handling VARCHAR(400) NOT NULL,
Kategori_typ CHAR(10) NOT NULL,
FOREIGN KEY (Kategori_typ) REFERENCES Kategori(typ)
);
CREATE TABLE FilmBild
(
Film_id INT NOT NULL,
FOREIGN KEY (Film_id) REFERENCES Film(id),
Bild_id INT NOT NULL,
FOREIGN KEY (Bild_id) REFERENCES Bild(id),
PRIMARY KEY (Film_id, Bild_id)
);
CREATE TABLE Kategori
(
typ CHAR(10) NOT NULL PRIMARY KEY
);
Det finns mycket mer att tänka på när man skapar SQL DDL, ta en titt i manualen på vad det finns för möjligheter med CREATE TABLE. Bland annat så kan man skapa index, olika begränsningar, default värden, teckenkodning och mycket mer. Läs referensmanualen för respektive databasserver så ser du vilka möjligheter som finns. Men, du klarar dig en bra bit med det här.
#10. Lista funktioner som databasen skall stödja (API)
En databas vore knappast spännande om man inte nyttjade den, därför är det viktigt att se över hur den skall nyttjas, vilka transaktioner den skall stödja. Skapa en lista med alla funktioner som databasen skall stödja. När du är klar har du databasens API.
Här ser du en delmängd till det API som behövs för vårt system.
- Lägg till ny Film.
- Uppdatera Film.
- Radera Film.
- Visa samtliga filmer.
- Visa information om en film tillsammans med betyg.
- Sök via informationen i filmer.
Därefter kan du gå vidare och implementera API:et genom att skriva SQL-koden för respektive transaktion. I detta skedet så kan du också överväga att nyttja vyer, funktioner, triggers och procedurer. Alla dessa är “programmerings-möjligheter” i en databas. Möjligheter som hjälper dig att hålla ett rent API och låter databasen göra det som den är duktig på.
Det är viktigt att du redan i databasen kan förbereda och skapa rapporter och svar som är så lika det slutliga svaret som möjligt. Detta underlättar för applikationsprogrammeraren och gör att vi får mindre och renare kod, både i databasen och i applikationerna.
#Dokumentation i Data Dictionary
#Varför DD?
Nu har vi en väl modellerad, delvis implementerad och förhoppningsvis snart en väl fungerande databas. Nu är det bara att fylla den med data och börja använda den, kanske koppla till en eller annan extern applikation?
Efter ett tag så behövs databasen modifieras eller vidareutvecklas, fler individer behöver veta hur databasen är uppbyggd och fler applikationer behövs kopplas mot databasen. Då är det bra att ha dokumenterat sin databas.
Detta gör vi i ett dokument, vår Data Dictionary, som är en dokumentation över vår databas. Det är alltid svårt att upprätthålla dokumentationen när systemet väl är i drift. Men, låt oss spara vårt material som vi gjort i samband med modelleringen och sätta samman det materialet till en Data Dictionary.
#Innehållsförteckning i en DD
En Data Dictionary, baserad på materialet från denna 10-stegs raket, kan se ut så här.
- Titel
- Introduktion.
- Beskrivning av databasen i ren text.
- Det konceptuella ER-diagrammet.
- Det logiska ER-diagrammet.
- SQL DDL.
- Databasens API inklusive SQL för att lösa API:et.
#Läs mer
#Boken Databasteknik
Läs följande kapitel i boken Databasteknik:
- Kapitel 2: ER-modellering
- Kapitel 4: Designprocessen
- Kapitel 5: Relationsmodellen
- Kapitel 6: Översättning från ER-modellen till relationsmodellen
Du kan även skumma och översiktligt gå igenom följande kapitel.
- Kapitel 3: Mer om datamodellering
#Inspelade föreläsningar
Det finns två inspelade föreläsningar som grundar sig på materialet från boken Databasteknik och de handlar om ER-modelleringen i den konceptuella fasen och om hur man översätter till relationsmodellen i den logiska modelleringsfasen. Se dem gärna som ett komplement till att läsa artikeln och för vidare studier i ämnet.
#Nätet
Det finns flera webbresurser som ger en bra introduktion och översikt till databasmodellering. Använd dessa som referenslitteratur eller för vidare studier i ämnet.
Wikipedia ger en bra beskrivande introduktion, översikt och beskriver även olika notationer för att rita ER-diagram.
Wikipedia har även en översikt av begreppet “Data dictionary” som vi använder (och ofta används) som begrepp på en dokumentation av en databas.
Det finns ett IBM paper av Davor Gornik beskriver hur UML kan användas i ER-modellering. Du hittar det i pdf-format via nedanstående länk.
Ett annat papper som hanterar UML i ER-modellering är skrivet av Robert A. Maksimchuk och Erik J Naiburg. Du når papperet via nedanstående länk.
#Revision history
- 2022-02-01: (F, mos) Förtydligande om att det finns tre föreläsningar totalt.
- 2021-02-10: (E, mos) Kompletterad med inspelade föreläsningar om ER-modellering och översättning till relationsmdoellen.
- 2021-01-31: (D, mos) Kompletterad med inspelad föreläsning.
- 2012-09-20: (C, mos) Flyttad från googledocs till dbwebb.
- 2009-09-02: (B, mos) Uppdaterad för att användas i kursen Databasteknik moment modellering.
- 2008-12-10: (A, mos) Första utgåvan
